/* CAT(1) */
I suppose I've been living under a rock for the past 15 years but I had never heard of a "Rich Header" until fairly recently. The Rich Header (RH) is a structure of data found in PE files generated by Microsoft linkers since around 1998. My interest was spurred a few months back when I saw the following Tweet which linked to an excellent article about this undocumented artifact.
The Undocumented Microsoft "Rich" Headerhttps://t.co/JzHZ8oeXlG
— DirectoryRanger (@DirectoryRanger) April 16, 2018
I highly recommend reading it but the TL;DR is that at some point Microsoft introduced a function into their linker which embeds a "signature" in the DOS Stub, right after the DOS executable, but before the NT Header. You've probably seen it a thousand times when looking at files and never realized it existed. Back in the early 2000's, when the existence of the header was known for a while, everyone originally assumed it included unique data to identify systems or people, such as with a GUID, and it spawned numerous conspiracy theories - they even nick named it "the Devil's Mark". Eventually someone got around to actually reverse engineering (RE) the linker and figured out how the structure of information was being generated and what it actually reflected. Turns out the tin-foils were half-right. The blog post linked above in the Tweet shows what is actually in them and, while not truly unique to a system or person, it can still serve for some identifying purposes to a certain degree. My interest was peaked!
Effectively, this structured data contains information about the tools used during the compilation of the program. So, for example, one entry in the array may indicate Visual Studio 2008 SP1 build 301729 was used to create 20 C objects. For each entry, a tool, an object type, and a "count" are represented. None of this is really super important at the moment but just know that on some level, there is a lightweight profile of the build environment that is encoded and stuffed into the PE file.
When I began reading more about this topic, I came across an article from Kaspersky stating they used Rich Header information to identify two separate pieces of malware with matching headers. This is exactly what I was hoping for so I read on. Back when the Olympic Destroyer campaign occurred, every vendor under the sun rushed to attribution - from Chinese APT to Russian APT and finally North Korean APTs. After the article throws some shade at Cisco Talos, they state the Rich Header found in one sample of the Olympic Destroyer wiper malware matched exactly with a previous sample used by Lazarus group, along with the fact that there was zero overlap across other known good or bad files. Sounded promising! Then they dive into the actual contents of the Rich Header though, an analyst at Kaspersky noted a major discrepancy. Specifically, a reference to a DLL within the wiper malware that didn't yet exist if the Rich Header tools were to be believed. The (older) Rich Header in the Lazarus sample showed it was compiled with VB6, but this DLL was introduced in later versions of VB. They concluded the Rich Header was planted as part of a false-flag operation.
In this case the Rich Header was used to disprove actor attribution - the reverse of what I expected but fascinating none the less. It's an interesting read but the main point I want to make is that an adversary had the foresight to use this lightweight profile as part of multiple false-flag plants to throw off researchers and put them on the path of inaccurate attribution. That, to me, implied that on some level it's a viable attribution mechanism if an adversary is going out of their way to plant false ones. There is some merit to the technique and, as such, what prompted me to write this blog. What I plan to do then is take you along as I look at Rich Headers and try to determine there place in the analysis phase of hunting. To do this, I'll try to answer the following questions:
- What opportunities for hunting does YARA provide as it stands today? What are the pro's and con's that I need to be aware of?
- Is there potential for actor, malware family, or campaign tracking?
- Can I prove or disprove relationships via Rich Headers?
- What are the benefits and limitations of the information held within the Rich Header?
Alright, without further ado then...
Rich Header Overview
It makes sense to start out by giving a quick overview of how the Rich Header is created. I won't be doing a deep-technical dive here because there are tons of great resources on it already, which I highly recommend reading.
So what does the Rich Header look like in the file?
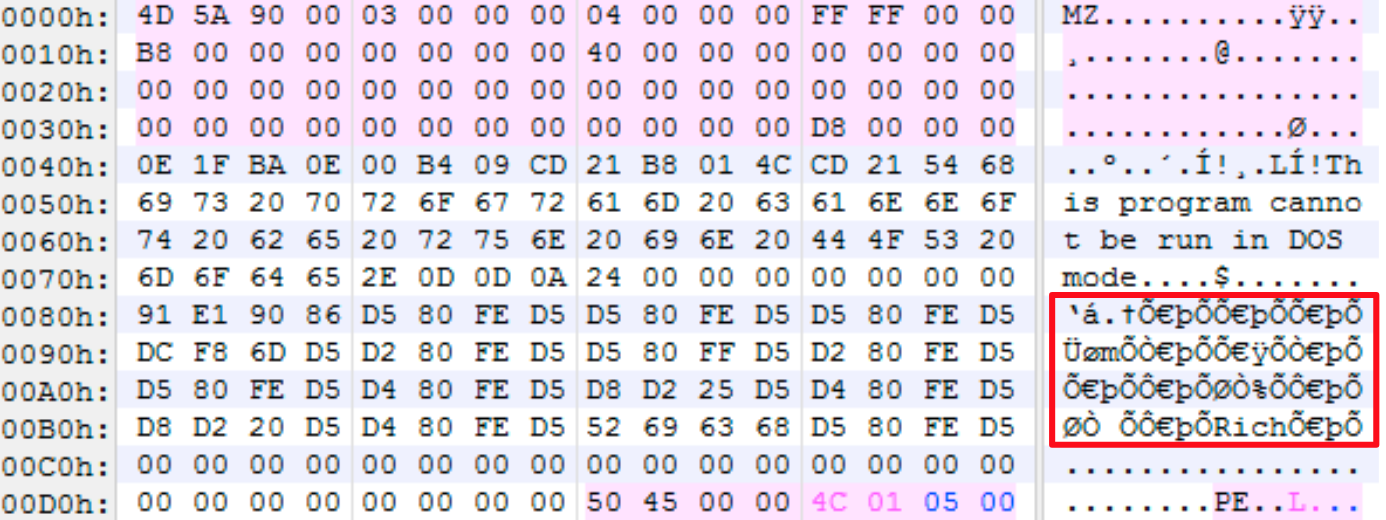
Like I said above, you've probably seen it a thousand times and never realized it. Before diving in, here are a handful of key characteristics you should be aware of.
- The Rich Header ANCHOR is the ASCII word "Rich" followed by a DWORD XOR key.
- The XOR key decodes every 4-bytes backwards until it decodes the ASCII word "DanS".
- The "DanS" keyword is followed by 3 DWORDs of null-bytes, which will be the XOR key before decoding.
- Each array entry is made up of 8 bytes and consists of two WORD values followed by a DWORD.
- Each 4-bytes of the WORD values are flipped to little endian.
- The first WORD is the Tool ID, which indicates the type of object the entry represents. (eg how many imports?)
- The second WORD is the Tool ID value, which indicates the actual tool. (eg Microsoft Visual Studio 7.1 SP1)
- The DWORD is the "count", which indicates the number of occurrences of whatever the first WORD represents. (eg 5 imported dlls)
- The XOR key is derived from adding the values of two separate custom checksum generations and then masking with 0xFFFFFFFF.
- The first checksum is generated from the bytes that make the DOS header, but with the e_lfanew field zeroed out.
- This e_lfanew field indicates the offset for the PE header, which isn't known prior to this computation.
- The second checksum is generated from the aggregate value of each array entry.
To parse this data out, I created a Python script (yararich.py) that will print out the structure while also generating YARA rules based off said structure. Below is an example of the parsed output.
[+] Parsed Rich Header
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x000C1C7B // entry 1
0x0094 | 0x00000001 // id12=7291, uses=1
0x0098 | 0x000A1F6F // entry 2
0x009C | 0x0000000B // id10=8047, uses=11
0x00A0 | 0x000E1C83 // entry 3
0x00A4 | 0x00000005 // id14=7299, uses=5
0x00A8 | 0x00041F6F // entry 4
0x00AC | 0x00000004 // id4=8047, uses=4
0x00B0 | 0x005D0FC3 // entry 5
0x00B4 | 0x00000007 // id93=4035, uses=7
0x00B8 | 0x00010000 // entry 6
0x00BC | 0x0000004D // id1=0, uses=77
0x00C0 | 0x000B2636 // entry 7
0x00C4 | 0x00000003 // id11=9782, uses=3
[+] Details
File: ae9a4e244a9b3c77d489dee8aeaf35a7c3ba31b210e76d81ef2e91790f052c85.bin
Clear Data: 44616E530000000000000000000000007B1C0C00010000006F1F0A000B000000831C0E00050000006F1F040004000000C30F5D0007000000000001004D00000036260B0003000000
Clear Data Hash: 0895C7ECCC58DECF2B8ED537BA6DCEEEF555B2229700894E986418F703F5E8E6
XOR Key: 0x2A497F97
Checksum Match: True
In this example, which is from the Olympic Destroyer wiper malware looked at in Kasperskys blog, you'll see the last entry in the array ("id11=9782, uses=3") displays three values. The ID of 9782 has been mapped to "Visual Basic 6.0 SP6", the object type of 11 indicates it will be C++ OBJ file created by the compiler, and then the "uses" value of 3 is how many of those object files were created.
I haven't been able to find any kind of truly comprehensive listing for the Tool ID/value mappings, but across the websites linked in this post you'll find various tables for them that cover most cases I've seen. These have been reverse engineered from the compilers/linkers over the years and also enumerated through extensive testing by diligent individuals by compiling a program, changing things, re-compiling and noting the differences.
YARA and Rich Headers
Alright, now that you have an idea of what information is available, I can talk about using YARA to hunt Rich Headers and some current limitations of this method. There are really four key parts to each Rich Header: the array itself and associated values, the XOR key, the integrity of the XOR key, and the full byte string which make up the entire Rich Header structure. These are effectively what you can utilize in YARA, minus verifying the integrity of the XOR key.
Throughout my analysis, I ran across quite a few YARA related gotcha's that I wanted to detail up front.
1) YARA's implementation of the Python PE module only parses out the Tool ID and the associated value (type of object). It does not take into account the "uses" count. This value, I feel, can be very important to the overall goal of using the Rich Header data as a profiling signature but there are cons to it as well. For example. there could be a major difference between a PE that used 4 source C files and 20 imports versus 200 source C files and 500 imports. Alternatively, if you used the count value you could miss related samples because the counts changed during the development of the malware, causing things like imports to change. I'll get into a concept of "complexity" for the Rich Headers later, but know that a higher complexity ensures a consistency across samples that means the coupling of only Tool ID/Object type is fine, whereas with a "low" complexity Rich Header would be easier to hunt on if counts were included.
2) In YARA there is not a concise way to establish the order of entries within the array when using the PE module as they are defined under the "conditions" section in YARA, thus not providing a mechanism to refer to the "location" (first match > second match). When you hunt with YARA, since the "uses" data is missing, you are limited to using the array entries in the PE module and will run into two problems. First, the order matters. The order in which the linker inserts these entries into the array, which is based on the input, should weigh into the idea of trying to match the same environment between samples and, if they are out of order, then even if the values were the same, it could be entirely different source code and layout.
Since Kasperky illustrated that the Rich Header is already on shaky ground in terms of how much you can trust them, making sure our rule is as precise as possible to match a specific environment takes a top priority.
Below is the output from a Hancitor malware sample.
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x007BC627 // entry 1
0x0094 | 0x00000002 // id123=50727, uses=2
0x0098 | 0x00937809 // entry 2
0x009C | 0x0000000D // id147=30729, uses=13
0x00A0 | 0x00010000 // entry 3
0x00A4 | 0x00000044 // id1=0, uses=68
0x00A8 | 0x00E19EB5 // entry 4
0x00AC | 0x00000007 // id225=40629, uses=7
0x00B0 | 0x00DE9EB5 // entry 5
0x00B4 | 0x00000001 // id222=40629, uses=1
The way this is represented in YARA follows.
rule UNORDERED_ARRAY {
condition:
pe.rich_signature.toolid(123,50727)
and pe.rich_signature.toolid(147,30729)
and pe.rich_signature.toolid(1,0)
and pe.rich_signature.toolid(225,40629)
and pe.rich_signature.toolid(222,40629)
}
Searching for this via VirusTotal will result in 527 hits (all of which are likely unrelated to Hancitor or the group behind it), but we can further refine this then by using the XOR encoded Tool ID/value entries, skipping every other 4-bytes (the "uses" value DWORD), and set the order via string match position in YARA.
FD 65 B2 38 B9 04 DC 6B B9 04 DC 6B B9 04 DC 6B
9E C2 A7 6B BB 04 DC 6B B0 7C 4F 6B B4 04 DC 6B
B9 04 DD 6B FD 04 DC 6B 0C 9A 3D 6B BE 04 DC 6B
0C 9A 02 6B B8 04 DC 6B 52 69 63 68 B9 04 DC 6B
This can be turned into the below YARA.
rule ORDERED_XOR {
strings:
$entry1 = { 9E C2 A7 6B }
$entry2 = { B0 7C 4F 6B }
$entry3 = { B9 04 DD 6B }
$entry4 = { 0C 9A 3D 6B }
$entry5 = { 0C 9A 02 6B }
condition:
@entry1[1] < @entry2[1]
and
@entry2[1] < @entry3[1]
and
@entry3[1] < @entry4[1]
and
@entry4[1] < @entry5[1]
}
This is effectively the same data but will return 5 hits, which is more accurate, and they are all actually related to Hancitor group; however, one major caveat to this method, and one that really makes it unfeasible in the end, is that the encoded values are of course tied to the XOR key. Womp womp. You'll recall that the XOR key is derived, in part, by the array and the DOS stub, thus if the the DOS stub is different or the Rich Header array is different, then the XOR key will follow suit and these won't match at all. At that point, you're better off just searching for the XOR key or raw/encoded data. It would be nice if YARA was patched to allow for ordering of the decoded array entries.
3) Next, the example above with Hancitor falls apart because of over-matching. Specifically, the above examples contain 5 entries. The last entry is always the linker and the one above that is usually the compiler entry, so we have 3 other entries related to the build environment. That's not a lot to go on and you'll frequently run into situations where samples with high entry counts can trigger a match simply due to having the same entries included. In general, I'd say the larger the array, the more likely it will be accurate and easier to search on but I'll prod this angle further during analysis.
I haven't extensively tested this next piece but a lot of the over matching seemed to stem from DLL's. The following is the parsed array from one of the matches pulled from the 500+ samples returned via the first Hancitor YARA example.
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x00C7A09E // entry 1
0x0094 | 0x00000002 // id199=41118, uses=2
0x0098 | 0x00DF520D // entry 2
0x009C | 0x00000004 // id223=21005, uses=4
0x00A0 | 0x00E0520D // entry 3
0x00A4 | 0x0000000C // id224=21005, uses=12
0x00A8 | 0x00E1520D // entry 4
0x00AC | 0x00000004 // id225=21005, uses=4
0x00B0 | 0x00DD520D // entry 5
0x00B4 | 0x00000004 // id221=21005, uses=4
0x00B8 | 0x00937809 // entry 6
0x00BC | 0x00000006 // id147=30729, uses=6
0x00C0 | 0x007BC627 // entry 7
0x00C4 | 0x00000003 // id123=50727, uses=3
0x00C8 | 0x00010000 // entry 8
0x00CC | 0x000000A8 // id1=0, uses=168
0x00D0 | 0x00E19EB5 // entry 9
0x00D4 | 0x0000000E // id225=40629, uses=14
0x00D8 | 0x00DC9EB5 // entry 10
0x00DC | 0x00000001 // id220=40629, uses=1
0x00E0 | 0x00DB520D // entry 11
0x00E4 | 0x00000001 // id219=21005, uses=1
0x00E8 | 0x00DE9EB5 // entry 12
0x00EC | 0x00000001 // id222=40629, uses=1
You'll note that the entries are also out-of-order from the Hancitor sample but I digress. In addition to patching YARA to allow for specifying ordered array entries, another useful feature to address over-matching would be a way to specify bounds for the rule entries, something like Sample A matches if it only contains these Y entries.
4) The last item I'll touch on is searching by XOR key and the raw data. I clump these together because they, for the most part, represent the same thing even though the XOR key figures in the PE DOS header/stub, which can differ between samples, while the array remains the same.
Below is an example of using the XOR key and the raw data (hashed to avoid conflicting characters which may be in the raw data, such as quotes) in YARA.
pe.rich_signature.key == 0x6BDC04B9
hash.sha256(pe.rich_signature.clear_data) == "0b5d6dfcaba9d377a7f23fd219d921438862d9a2c8009f363767c778f936acef"
Note that the hash must be lowercase in YARA. I haven't looked into the underlying code to validate but it appears this function is doing a string comparison and if you use uppercase in the hash it will fail to match. Either way, both of those will return the same 4 hashes, which isn't unexpected.
When doing any serious hunting you'll want to attack Rich Headers from multiple angles. A full YARA rule generated from my script, using the above Hancitor sample, is below.
import "pe"
import "hash"
// File: hancitor/291fc089688d7b6dff031022298d1b939746f3d6dafbb5a419f2a2bbc29f614d_S1.exe
rule UNORDERED_ARRAY {
condition:
pe.rich_signature.toolid(123,50727)
and pe.rich_signature.toolid(147,30729)
and pe.rich_signature.toolid(1,0)
and pe.rich_signature.toolid(225,40629)
and pe.rich_signature.toolid(222,40629)
}
rule ORDERED_XOR {
strings:
$entry1 = { 9E C2 A7 6B }
$entry2 = { B0 7C 4F 6B }
$entry3 = { B9 04 DD 6B }
$entry4 = { 0C 9A 3D 6B }
$entry5 = { 0C 9A 02 6B }
condition:
@entry1[1] < @entry2[1]
and
@entry2[1] < @entry3[1]
and
@entry3[1] < @entry4[1]
and
@entry4[1] < @entry5[1]
}
rule XOR_KEY {
condition:
pe.rich_signature.key == 0x6BDC04B9
}
rule CLEAR_DATA {
condition:
hash.sha256(pe.rich_signature.clear_data) == "0b5d6dfcaba9d377a7f23fd219d921438862d9a2c8009f363767c778f936acef"
}
Case Studies
I didn't have an easy way to directly access Rich Headers so I created a corpus of samples to test against. To start, I downloaded 21,996 samples which covered a wide range of malware families, actors, or campaigns - 962 different ones to be exact. These were identified by iterating over identifiers (eg "APT1", "Operation DustySky", "Hancitor") and, after removing duplicate files, I was left with a total of 17,932 unique samples. Out of that, 14,075 included Rich Header values, which was 78.4% of the total and seemed like a good baseline to begin testing against. This also highlights just how prevalent Rich Headers are in the wild.
I've parsed out the Rich Header from every one of these files and will be using that data for my analysis. As there is far too much to go through individually, I approached the problem with various analytical lenses and then explored interesting aspects that reared up during this exercise.
Rich Header Overlaps
The first thing I was really interested in was whether the Rich Headers overlapped between those identifiers as it may be a strong indicator for profiling. A lot of this analysis will be referencing the XOR keys as I feel these are really the defining feature of the Rich Header when it comes to hunting, since it encompasses everything.
Below are the top 10 XOR keys by unique sample count that shared more than one identifier.
1009 || 0xB6CCD171 || APT33,DropShot,TurnedUp
0547 || 0x89A99A19 || Grabsir,HideProc,POSFight,PoisonIvy,TinyNuke,TrickBot,V0lk
0215 || 0xD180F4F9 || 7ev3n,Paskod,PoisonIvy,TrickBot
0112 || 0xFA28276F || Gh0st,Zegost
0107 || 0x2F3719A6 || LazarusGroup,OpBlockbuster
0101 || 0x7DFEF65C || KillDisk,ModifyMBR,Petya
0090 || 0x69EB1175 || Alina,BigBong,Carbanak,CryptInfinite,CryptoBit,GodzillaLoader,Goopic,GovRAT,Hancitor,ModifyDNSSearchOrder,NitlovePOS,NitlovePOSDownloader,Odinaff,Oztratz,PClock,PandaBanker,PhiladelphiaRansom,RanserKD,ResolveParkedDomain,SevenPointedDagger,SundownEKMalwarePayload,TinyNuke,Toshliph,V0lk,ZCrypt,Zeprox
0073 || 0x89A56EF9 || CoreBot,KHRAT,OpSMNPoisonIvy,PoisonIvy
0072 || 0x886973F3 || AldiBot,Backoff,BlackShades,Blohi,Carbanak,CrypAura,CryptoDevil,DHSpyware,HideProc,Jorik,Maktub,NewPOSThings,Packrat,PoisonIvy,PonyForxx,PowerShellCaretObfuscation,Punkey,ShortenedURLRequest,TrickBot,Troldesh,UsesDynamicDNS,V0lk,Vilsel,iRAT
0066 || 0xC1FC1252 || Carbanak,CryptoJoker,CryptoWire,Downeks,GazaCyberGang,Ishtar,NICIndiaAttack,PClock,Patchwork,PhiladelphiaRansom,PowerShellEncodedCommand,PowershellEmpireLauncher,PowershellLoadDotNet,PsExec,TinyNuke,V0lk,WordCallsWinHTTPDll,njw0rm
0xB6CCD171 - APT33,DropShot,TurnedUp
Looking at the first entry, 1,009 unique hashes across three identifiers. TurnedUp was a piece of malware used in the DropShot campaign by APT33 so starting off, we have a known relationship between the samples. Furthermore, they have a fairly sizable Rich Header with 10 entries so it's less likely to be "generic". In total, I have 1,014 APT33 samples and 999 of them shared this XOR key. Looking at one of the samples which doesn't share that key highlights a previous point I made regarding the "counts". Check out the below parsed Rich Header output for 0xB6CCD171 and the output of 0xD78F6BA1 right next to it; I've highlighted the differences which exist only in the "uses" field.
Offset | Data // Meaning Offset | Data // Meaning
-------------------------------------------------- --------------------------------------------------
0x0090 | 0x00984E93 // entry 1 0x0090 | 0x00984E93 // entry 1
0x0094 | 0x00000002 // id152=20115, uses=2 0x0094 | 0x00000002 // id152=20115, uses=2
0x0098 | 0x00AB9D1B // entry 2 0x0098 | 0x00AB9D1B // entry 2
0x009C | 0x0000003E // id171=40219, uses=62 0x009C | 0x0000003D // id171=40219, uses=61
0x00A0 | 0x009E9D1B // entry 3 0x00A0 | 0x009E9D1B // entry 3
0x00A4 | 0x0000001A // id158=40219, uses=26 0x00A4 | 0x0000001A // id158=40219, uses=26
0x00A8 | 0x00AA9D1B // entry 4 0x00A8 | 0x00AA9D1B // entry 4
0x00AC | 0x000000AB // id170=40219, uses=171 0x00AC | 0x000000AB // id170=40219, uses=171
0x00B0 | 0x00837809 // entry 5 0x00B0 | 0x00837809 // entry 5
0x00B4 | 0x00000001 // id131=30729, uses=1 0x00B4 | 0x00000001 // id131=30729, uses=1
0x00B8 | 0x00010000 // entry 6 0x00B8 | 0x00010000 // entry 6
0x00BC | 0x000000B0 // id1=0, uses=176 0x00BC | 0x000000CE // id1=0, uses=206
0x00C0 | 0x00937809 // entry 7 0x00C0 | 0x00937809 // entry 7
0x00C4 | 0x00000013 // id147=30729, uses=19 0x00C4 | 0x00000015 // id147=30729, uses=21
0x00C8 | 0x00AF9D1B // entry 8 0x00C8 | 0x00AF9D1B // entry 8
0x00CC | 0x0000000E // id175=40219, uses=14 0x00CC | 0x0000000E // id175=40219, uses=14
0x00D0 | 0x009A9D1B // entry 9 0x00D0 | 0x009A9D1B // entry 9
0x00D4 | 0x00000001 // id154=40219, uses=1 0x00D4 | 0x00000001 // id154=40219, uses=1
0x00D8 | 0x009D9D1B // entry 10 0x00D8 | 0x009D9D1B // entry 10
0x00DC | 0x00000001 // id157=40219, uses=1 0x00DC | 0x00000001 // id157=40219, uses=1
So what does this mean? The entry "id171=40219" corresponds to VS2010 SP1 build 40219 and indicates 62 C++ files were linked on the left, 61 on the right. Similarly for the next highlighted entry, this is a count of the imported symbols and you can see on the right it's grown by quite a bit. Finally, with entry "id147=30729", which corresponds to VS2008 SP1 build 30729, it indicates on the left that it linked 19 DLL's while on the right is 21. This helps establish a pattern of consistency between the samples in that the structure of the array remained the same but, with increasing counts, was likely modified over time.
Outside of the Rich Header, we can take a look at some other artifacts and see if the samples remain consistent in any other ways.
PDB:
0xB6CCD171 File Name,c:\users\xman_1365_x\desktop\homework\13930308\bot_70_fix header_fix_longurl 73_stableandnewprotocol - login all\release\bot.pdb
0xD78F6BA1 File Name,c:\users\xman_1365_x\desktop\new folder (2)\2015_4-2\bot_70_fix header_fix_longurl 73_stableandnewprotocol - login all\release\bot.pdb
Compile Times:
0xB6CCD171 TimeDateStamp,0x538B07F4 (Sun Jun 01 07:01:08 2014)
0xD78F6BA1 TimeDateStamp,0x55012B51 (Thu Mar 12 01:59:45 2015)
Shared Strings:
deskcapture.jpg
User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:23.0) Gecko/20100101 Firefox/23.0
StikyNote.exe
\msdtcvtr.bat
Based on the above information, it would appear the original author (as indicated by the PDB path retained in the debug information when it was compiled) later updated this particular malware source. The compile times show 2014 and 2015 respectively and the PDB path on the newer one reflects the 2015 information. Outside of that, the user path is the same and they share a number of strings for dropped file names, User-Agent, so on and so forth. Either way, they seem to confirm the samples are related which means that the Rich Header in this case is likely accurate and, given that it's not particularly generic, should be suitable for hunting.
0x69EB1175 - Alina,BigBong,Carbanak,CryptInfinite,CryptoBit, ...
Alright, so let's take a look at a key with groups that seems to be unrelated. For XOR Key 0x69EB1175 there are 26 different identifiers and they appear to be all over the place - cryptominers, droppers, trojans, ransomware, etc. I've taken the parsed Rich Header and annotated it with what I could find regarding the Tool Id values.
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x005F0FC3 // entry 1
0x0094 | 0x00000002 // id95=4035, uses=2 * VS2003 (.NET) build 4035 / C objects
0x0098 | 0x00010000 // entry 2
0x009C | 0x0000009E // id1=0, uses=158 * Total imports
0x00A0 | 0x005D0FC3 // entry 3
0x00A4 | 0x00000011 // id93=4035, uses=17 * VS2003 (.NET) build 4035 / Imports
0x00A8 | 0x00302354 // entry 4
0x00AC | 0x0000000A // id48=9044, uses=10 * "Utc12_2_C"
0x00B0 | 0x000606C7 // entry 5
0x00B4 | 0x00000001 // id6=1735, uses=1 * VS98 (6.0) SP6 cvtres build 1736
If we assume VS98 and "Utc12_2_C" are the compiler/linker, then there is really just one additional Tool (but two object types) in use for this Rich Header. That doesn't build a lot of confidence in being unique so for now we'll just define this as low complexity/generic. Given that, I pulled a couple of samples into an analysis box to see what similarities, if any, exist between them. Almost immediately it's apparent what the commonality here is - everybody's favorite friend...Nullsoft's NSIS Installer! This makes sense why it spans so many disparate malware families and campaigns. NSIS Installer will compile a brand new executable so the entire "development" environment is tied to this version of NSIS. This also means the Rich Header is effectively useless for defining anything but NSIS, which does have value in its own right but not the purpose of this exploration. Different versions of NSIS most likely have different Rich Headers that are embedded when it compiles the scripts into the executable, but I haven't tested this.
0xD180F4F9 - 7ev3n,Paskod,PoisonIvy,TrickBot
Picking another key to look at, 0xD180F4F9 has samples matching identifiers for 7ev3n, Paskod, PoisonIvy, and TrickBot malware families; however, it has even less entries than the previous example.
Offset | Data // Meaning
--------------------------------------------------
0x0090 | 0x000E1C83 // entry 1
0x0094 | 0x00000001 // id14=7299, uses=1
0x0098 | 0x00091F69 // entry 2
0x009C | 0x0000000B // id9=8041, uses=11
0x00A0 | 0x000D1FE9 // entry 3
0x00A4 | 0x00000001 // id13=8169, uses=1
While not high in entry volume, all of these ToolID and types are not documented across any of the sources that I frequent to look them up. That alone is interesting to me - possibly newer or more obscure tools. Either way, assuming one is the compiler and one is the linker than we have but one additional "Tool" so it's extremely generic.
Taking a look at a PoisonIvy and TrickBot sample, they both match signatures for Microsoft Visual Basic v5.0-6.0 and each have one imported library "msvbvm60.dll". A general review of the samples doesn't show anything that looks related but these strings stand out as interesting.
C:\Program Files\Microsoft Visual Studio\VB98\VB6.OLB
C:\Program Files (x86)\Microsoft Visual Studio\VB98\VB6.OLB
The "VB6.OLB" file existed in two different paths at compilation time. If these strings are to believed, this would indicate a separate build environment. There does appear to be some similarity in the Visual Basic project files being somewhat randomized. Not a strong link but it's something. The language packs used in the binaries, along with the username listed in the one VBP, would make me lean towards it still being unrelated.
A*\AD:\ZmbSsZ1q6c4yn7ph\pyzjwmbyocjn.vbp
A*\AC:\Users\;5:A0=4@\Tesktop\PNYINp6J1\PNYINp6J1\CDsGT9YqpuFCQu\EqZt8h.vbp
I believe this is likely another instance where the Rich Header is primarily useful for product identification and not much else unfortunately.
Group Overlap
Below is a table of the aforementioned XOR keys and a short blurb about each. I've highlighted the ones in RED which seemed to support plausible attribution
0xB6CCD171 - Known cluster between APT33/DropShot/TurnedUp. RH has 10 entries.
0x89A99A19 - VB5 with varied VBP paths. Noted one reference to a school project. RH has 3 entries.
0xD180F4F9 - Nullsoft NSIS as discussed before. RH has 5 entries.
0xFA28276F - Samples were packed with either UPX or Themida. Share icons, multiple file paths, API's, and similar domains. RH has 13 entries.
0x2F3719A6 - Known cluster between Lazarus/Operation Blockbuster. RH has 8 entries
0x7DFEF65C - UPX packed and all are the same file. Original "Petya" identifier is inaccurate I believe. RH has 10 entries.
0x69EB1175 - Nullsoft NSIS packer. RH has 5 entries.
0x89A56EF9 - Only contains linker/compiler, low entry count. RH has 2 entries.
0x886973F3 - VB6 but otherwise samples are all over the place, RH all but useless in this one. RH has 1 entry.
0xC1FC1252 - AutoIT based malware. RH has 13 entries.
There are a couple of interesting observations I made while going through these. First, it seems clear that the Rich Header can be useful for identifying software that generates new executables, eg NSIS and AutoIT. Overall I'd say anything with a large disparate set of identifiers is going to be created through some automated tool or have a low complexity array which is likely to just be picked up by unrelated samples. All of the "good" hits included more complex Rich Headers, when not built by automated tools, and that seems like a decent value-gauge. I felt around 8-10 was a sweet spot for "complexity".
Second, traditional packers like UPX and Themida do not modify the actual DOS Header/Stub so the Rich Header, in the case of 0xFA28276F, remains tied to the packed executable. As such, it was able to identify the underlying malware through the packer even though multiple layers of obfuscation were employed. This is a solid match in my opinion and also a pretty cool potential window into embedded malware.
Finally, there is some value when you look at dynamic analysis. As the Rich Header is a static feature, it allows another opportunity to identify samples that may otherwise fail to detonate in a sandbox. I was able to identify 15 unknown Brambul malware samples associated to Lazarus group by Rich Header alone as the samples had failed to actually detonate/do anything of note within a sandboxed environment. That's pretty handy.
Raw XOR Keys
The next phase of analysis I'll look at is from the angle of just raw XOR key volume. The below are the Top 20 XOR key counts and the identifiers for each key. For the keys previously analyzed I've just marked with a double-dash and will skip talking about here.
1009 0xB6CCD171 // --
0547 0x89A99A19 // --
0233 0x00A3CC80 // GandCrab (RH 11 entries)
0215 0xD180F4F9 // --
0183 0xD0A79B13 // GandCrab (RH 11 entries)
0165 0xF5740263 // GandCrab (RH 11 entries)
0124 0x9D2100DB // GandCrab (RH 7 entries)
0123 0xD97E80D5 // Qakbot (RH 5 entries)
0115 0x7BD6FBAB // GandCrab (RH 8 entries)
0112 0xFA28276F // --
0110 0x00A3CCE0 // GandCrab (RH 11 entries)
0107 0x2F3719A6 // --
0101 0x7DFEF65C // --
0090 0x69EB1175 // --
0079 0x7497C648 // GandCrab (RH 7 entries)
0073 0x89A56EF9 // --
0072 0xD5FE80D5 // Qakbot (RH 5 entries)
0072 0x886973F3 // --
0066 0xC1FC1252 // --
0066 0x7563E767 // GandCrab (RH 8 entries)
Looking at the list, the obvious repetition of GandCrab and Qakbot really stands out so I'll dive into each of these.
GandCrab
Out of the 1,075 GandCrab listed in the Top 20, every single one of them triggered a signature mismatch in my script. This means that the extracted XOR key was found to be different than what the script generated when it rebuilt the Rich Header XOR key. This is a clear sign of tampering and manipulation.
Looking at the set with the extracted XOR key of 0x00A3CC80 shows that every single hash has a different generated key with no overlap across the set. Upon further inspection, this is not caused by the actual Rich Header information, which is consistent between each sample, but due to the DOS Stub, which is factored into the algorithm that generates the Rich Header XOR key. Below shows the DOS Stub from two samples.
Samples 1:

Sample 2:

The DOS Stub is an actual DOS executable that the linker embeds in your program which simply prints the familiar "This program cannot be run in DOS mode" message before exiting. It appears that the bytes which account for the beginning of the message "This progra" are being overwritten after the Rich Header is inserted.
31 30 32 30 00 E9 03 17 63 2B 74 1020.é..c+t
31 30 33 34 00 1D CE 92 0A 1A 79 1034..Î’..y
Four ASCII numerals followed by a null byte followed by six bytes. For this particular XOR key, the initial ASCII of the four bytes are listed below.
1018 1035
1020 1036
1023 1037
1024 1038
1026 1043
1027 1045
1030 1047
1034 1049
The six bytes after the null didn't stand out as having any observable pattern. I read through a handful of GandCrab blogs from the usual suspects and didn't see any mention of this particular artifact. Additionally, I checked the other XOR keys in this list to see if they had similar behaviors, which they all did. Some of the keys didn't modify the initial four bytes but all included the null followed by the six bytes.
As this artifact seems to be unknown, I was curious if it's possibly campaign related or maybe some sort of decryption key. I ended up loading one of these samples into OllyDbg with a hardware breakpoint on access to any of the bytes in question. At some point the sample ends up overwriting the entire DOS Header and DOS Stub with a different value which triggered the breakpoint. The sample proceeds to unpack an embedded payload which contained its own Rich Header entry.
Searching my sample set for the new Rich Header (0xEC5AB2D9) led me to five other GandCrab samples. A quick pivot on the temporal aspect of these 5 samples, along with the XOR key I've been looking at, shows the 233 0x00A3CC80 samples starting to appear in the wild on 19APR2018 with a huge ramp up between 23APR2018-25APR2018, while the 5 samples which shared the newly extracted XOR key first appeared on 22APR2018, one day before the campaign kicked into high gear. I did a quick check on the rest of the GandCrab in this list and they are all from that time frame, but samples as recent as yesterday (months after April), show the same pattern, with the most recent sample displaying "1018" for the first four bytes. Interesting stuff to be sure and anytime I see an observable pattern I tend to think it's significant, but that would be a tangent for a separate blog. Either way, this was a good example of signature mismatch and why it's important to check Rich Headers on embedded/dropped payloads. These particular modifications add credibility to the idea that these samples were produced by the same environment and so, in this case, the Rich Headers led to artifacts that can be coupled together for profiling.
Qakbot
Shifting over to the two Qakbot entries, both XOR keys were from samples delivered during the same couple of days. One characteristic both XOR keys showed was that they, within their respective key group, were all the same file size except a small cropping of outliers in the XOR key 0xD5FE80D5. Specifically, 61 of the samples with that specific key are 548,864 bytes but there is 10 samples at 532,480 bytes and one sample with 520,192 byte. It's always interesting when you see outliers like this when looking at a large sample set. I continued by analyzing a sample from each file size and they all share the same dynamic behaviors, along with a few static ones, but otherwise they appear quite different. For example, they each import 3 libraries and 7 symbols but none of them are the same - this also just looks wrong and out of place based on my experience.
Upon closer inspection, Qakbot is using some sort of packer so, after the success of embedded payloads from the GandCrab work, I manually unpacked one sample from each of the three file sizes to see if anything stood out. We know the files are the same in terms of family already due to my collection method, but the unpacked payloads all matched 225 functions and over a thousand basic blocks, so that adds a lot of weight to the idea of the malware being related. When I looked at the unpacked samples, they each had their own respective Rich Headers so I've dug in a bit more here. Keep in the mind that the question I'm interested in is whether we can use these to determine if they were created by the same actor or in the same environment.
Below are the parsed Rich Headers for the 3 samples and I've sorted them from left to right based on their listed compile times, which incidentally aligns perfectly from smallest to largest of the original files. That is to say the 520,192 byte files embedded payload was compiled first and the 548,864 byte files embedded payload was compiled last.
0xDCE3EAC8 4223... 19DEC2017 04:51:12 0x6D28F629 8e0f... 29JAN2018 09:10:34 0xAE08C3FD e4de... 16APR2018 10:24:55
Offset | Data // Meaning Offset | Data // Meaning Offset | Data // Meaning
-------------------------------------------- -------------------------------------------- ------------------------------------------
0x0090 | 0x00837809 // entry 1 0x0090 | 0x00937809 // entry 1 0x0090 | 0x00937809 // entry 1
0x0094 | 0x00000003 // id131=30729, uses=3 0x0094 | 0x00000013 // id147=30729, uses=19 0x0094 | 0x00000015 // id147=30729, uses=21
0x0098 | 0x00AB9D1B // entry 2 0x0098 | 0x00010000 // entry 2 0x0098 | 0x00010000 // entry 2
0x009C | 0x00000001 // id171=40219, uses=1 0x009C | 0x0000007E // id1=0, uses=126 0x009C | 0x00000083 // id1=0, uses=131
0x00A0 | 0x00937809 // entry 3 0x00A0 | 0x00837809 // entry 3 0x00A0 | 0x00837809 // entry 3
0x00A4 | 0x00000013 // id147=30729, uses=19 0x00A4 | 0x00000004 // id131=30729, uses=4 0x00A4 | 0x00000004 // id131=30729, uses=4
0x00A8 | 0x00010000 // entry 4 0x00A8 | 0x000F0C05 // entry 4 0x00A8 | 0x000F0C05 // entry 4
0x00AC | 0x0000007C // id1=0, uses=124 0x00AC | 0x00000001 // id15=3077, uses=1 0x00AC | 0x00000001 // id15=3077, uses=1
0x00B0 | 0x000F0C05 // entry 5 0x00B0 | 0x00AA9D1B // entry 5 0x00B0 | 0x00AA9D1B // entry 5
0x00B4 | 0x00000001 // id15=3077, uses=1 0x00B4 | 0x00000038 // id170=40219, uses=56 0x00B4 | 0x00000038 // id170=40219, uses=56
0x00B8 | 0x00AA9D1B // entry 6 0x00B8 | 0x009D9D1B // entry 6 0x00B8 | 0x009D9D1B // entry 6
0x00BC | 0x00000037 // id170=40219, uses=55 0x00BC | 0x00000001 // id157=40219, uses=1 0x00BC | 0x00000001 // id157=40219, uses=1
0x00C0 | 0x009D9D1B // entry 7
0x00C4 | 0x00000001 // id157=40219, uses=1
In addition, I've listed out what each entry correlates to; however, the 0xDCE3EAC8 embedded payload includes one additional CompID (171).
171 = Utc1600_CPP || [C++] VS2010 SP1 build 40219
---------------------------------------------------
147 = Implib900 || [Imp] VS2008 SP1 build 30729
001 = Import0 || Total imports
131 = Utc1500_C || [ C ] VS2008 SP1 build 30729
015 = Masm710 || [ASM] VS2003 (.NET) build 3077
170 = Utc1600_C || [ C ] VS2010 SP1 build 40219
157 = Linker1000 || [LNK] VS2010 SP1 build 40219
Alright, first off if you look at the tools listed in the Rich Header above, you can see the payloads were built with components from VS2K8/10 SP1 with a specific build number that remains consistent across the 120 day period. Furthermore, you can see the "count" values increasing for some of the entries too. Now, this isn't rocket science but the idea that as a developer continues working on their program, the code base will usually increase as new functionality is introduced. This could directly translate into more imports/objects and thus increases in these counts when compiled. The specific increases can be viewed here.
Imports for VS2K8 [147] 019 -> 019 -> 021
C Objects for VS2K8 [131] 003 -> 004 -> 004
--------------------------------------------
C Objects for VS2K10 [170] 055 -> 056 -> 056
--------------------------------------------
Total imports [001] 124 -> 126 -> 131
Another thing that stands out is that the earliest file included an entry for C++ object files created by the compiler that were later not present, along with the order of CompID 131 and 147 being flipped. All of this evidence seems to indicate a reordering of code that again may be related to development. Finally, the most interesting artifact from earliest embedded payload is that it was compiled with the `/DEBUG` flag on and contains a path to the PDB.
j:\projects\qbot3\dllinject\release\win32\qbot_main_exe.pdb
Increasing counts for objects, a temporal and file size alignment, and a solid consistency of entries across the set shows, to me, a clear pattern consistency across the embedded payloads that establish they were all created in the same environment by the same actor.
When talking about OPSEC, the more the bad guys have to worry about the more likely it is they'll screw up. Using the Rich Header from embedded payloads seems to be a very successful technique for painting a fairly convincing picture that makes contextual sense for attribution.
Conclusions
Wrapping things up then, I think the most important takeaway is essentially what Kaspersky showed - Rich Headers are NOT to be trusted. They are simply static bytes in a file and can be manipulated like anything else, along with the fact that adversaries are actively already doing this. Rich Headers should be treated as a supporting artifact that can provide a lot of contextual value to your analysis and can help in attribution. In addition to that, the most "valuable" Rich Headers seem to be the ones with a high complexity and large entry count. These offer a more granular picture of the environment within which the program was constructed.
What I hope I've shown through this analysis though is that Rich Headers shouldn't be written off entirely. They are like more nuanced then I originally thought they would be and they can provide context by establishing patterns in environmental details. This context is enhanced when you start peeling away layers of packed/embedded payloads. Finally, the meta data contained within Rich Headers can provide extremely useful context to other expected artifacts that should be found in a binary and vice versa.
Hopefully this proves to be helpful to other analysts out there getting started with Rich Headers and provide some insight into the pro's and con's of what Rich Headers can offer.
*EDIT - 12AUG2018*
Received a few DM's and e-mails containing additional links and asking for more info so I decided to just add a short resources section for others interested in learning more.
Resources
Mappings for ToolId/Obj Types
- https://github.com/JusticeRage/Manalyze/blob/master/manape/nt_values.cpp
- https://gist.github.com/skochinsky/07c8e95e33d9429d81a75622b5d24c8b
- https://github.com/agrajag9/getrichlaikaboss/blob/master/comp_ids.txt
Blogs about Rich Headers from a RE perspective
Blogs about Rich Headers from a Threat perspective
- The devil’s in the Rich header
- OlympicDestroyer is here to trick the industry
- Yara and Rich Headers are full of win
- Detecting anomalies in the RICH header
White paper/Con preso on the subject
- Finding the Needle: A Study of the PE32 Rich Header and Respective Malware Triage
- Revealing the Machine A Study of the Rich Header and Respective Malware Triage